Introducing Plotwise, the slightly weird film explorer
Running a recommendation engine off of HTML and 5 MB of JSON

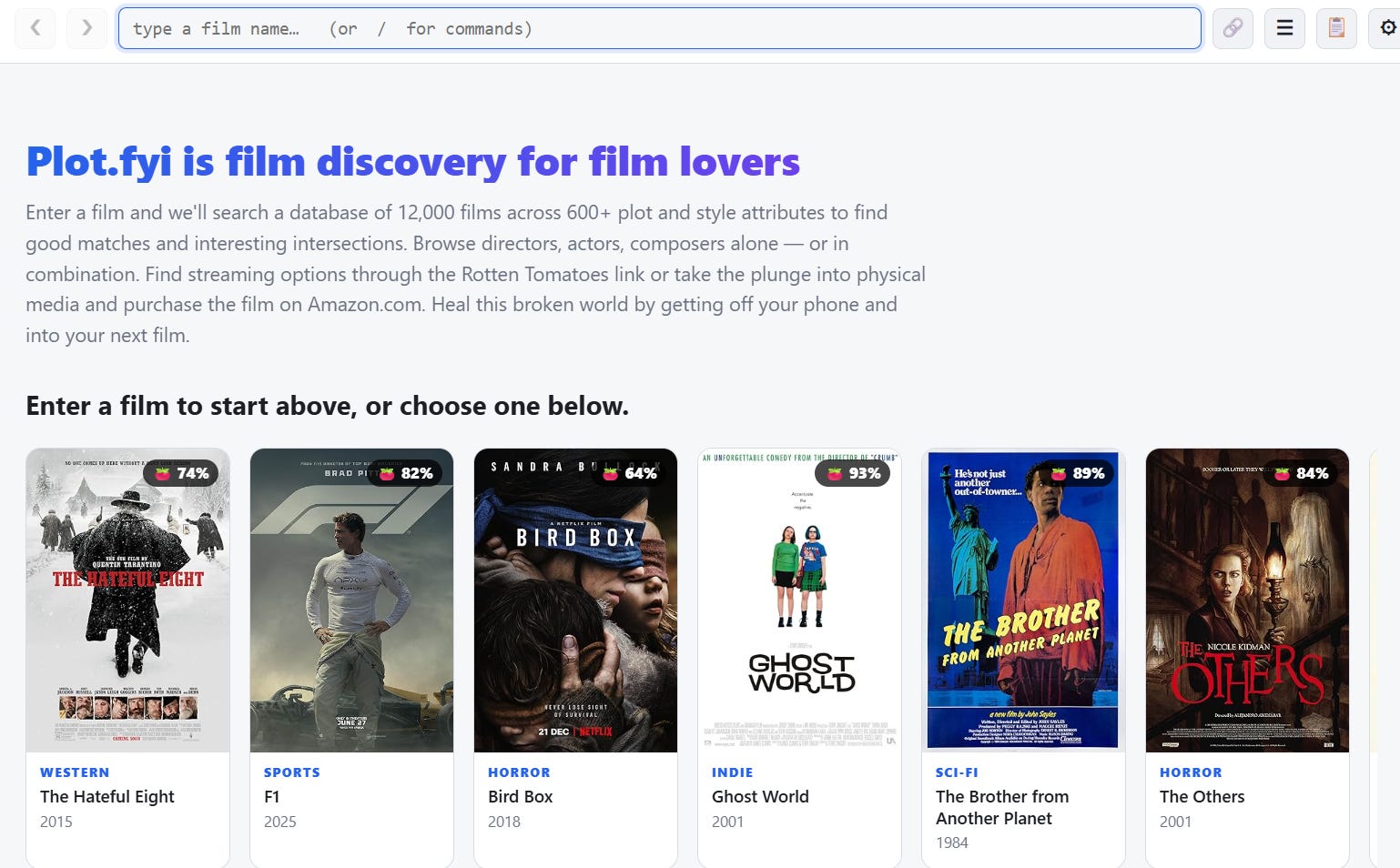
UPDATE: Plotwise is now Plot.fyi, and you should check it out. The post below refers to an earlier version called plotwise.
Plotwise, the film explorer idea I’ve been working on for the past month or so, is up.
It’s a tool for film geeks, and it’s not particularly user friendly at the moment. I mainly built it for my own use, and wasn’t planning to publish it until I was surprised how well it worked.
I’ll talk about how I built it later but here’s what you can do with it.
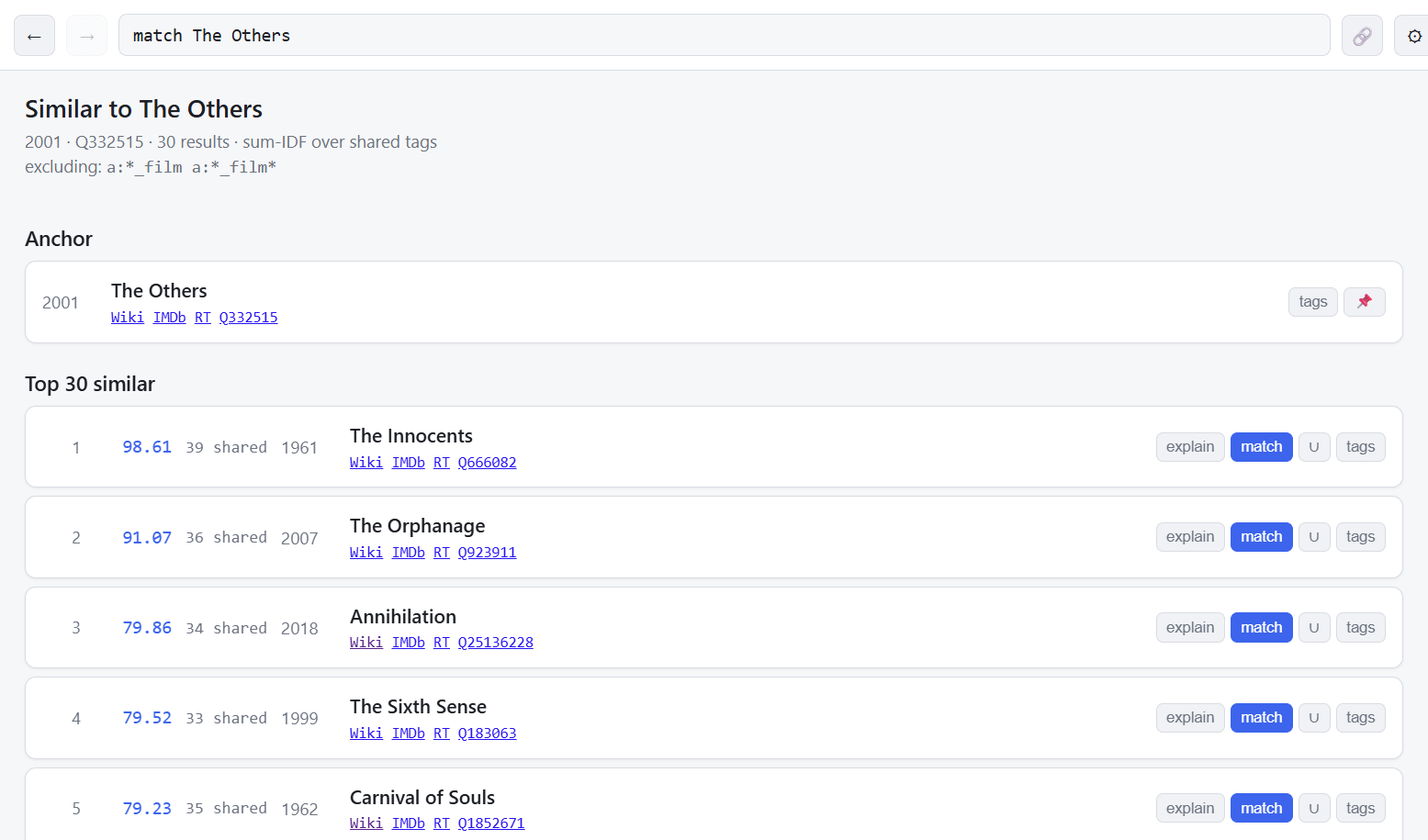
You can find matches for any film in the database (there’s 10,000+ films). Here’s matches for The Others. You get this by typing in “match The Others” in the command line.
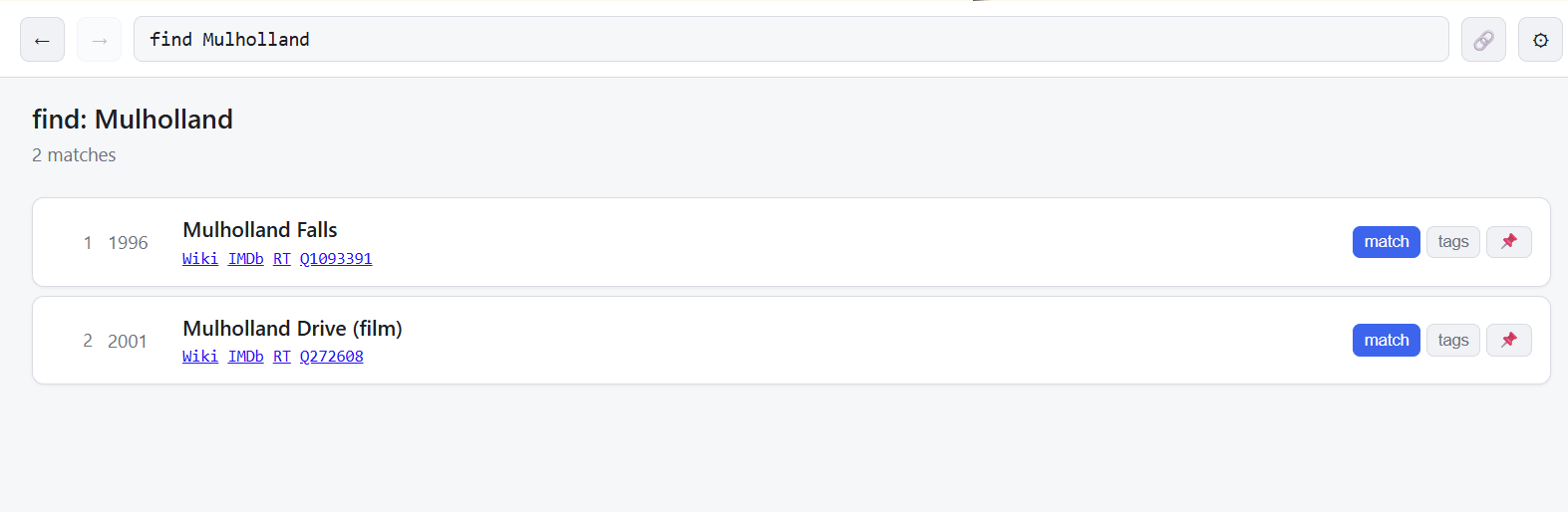
If you can’t quite remember the name, type “find” plus a word from the title, as here with find Mulholland (if you screw up spelling I can’t help).
Then click in.
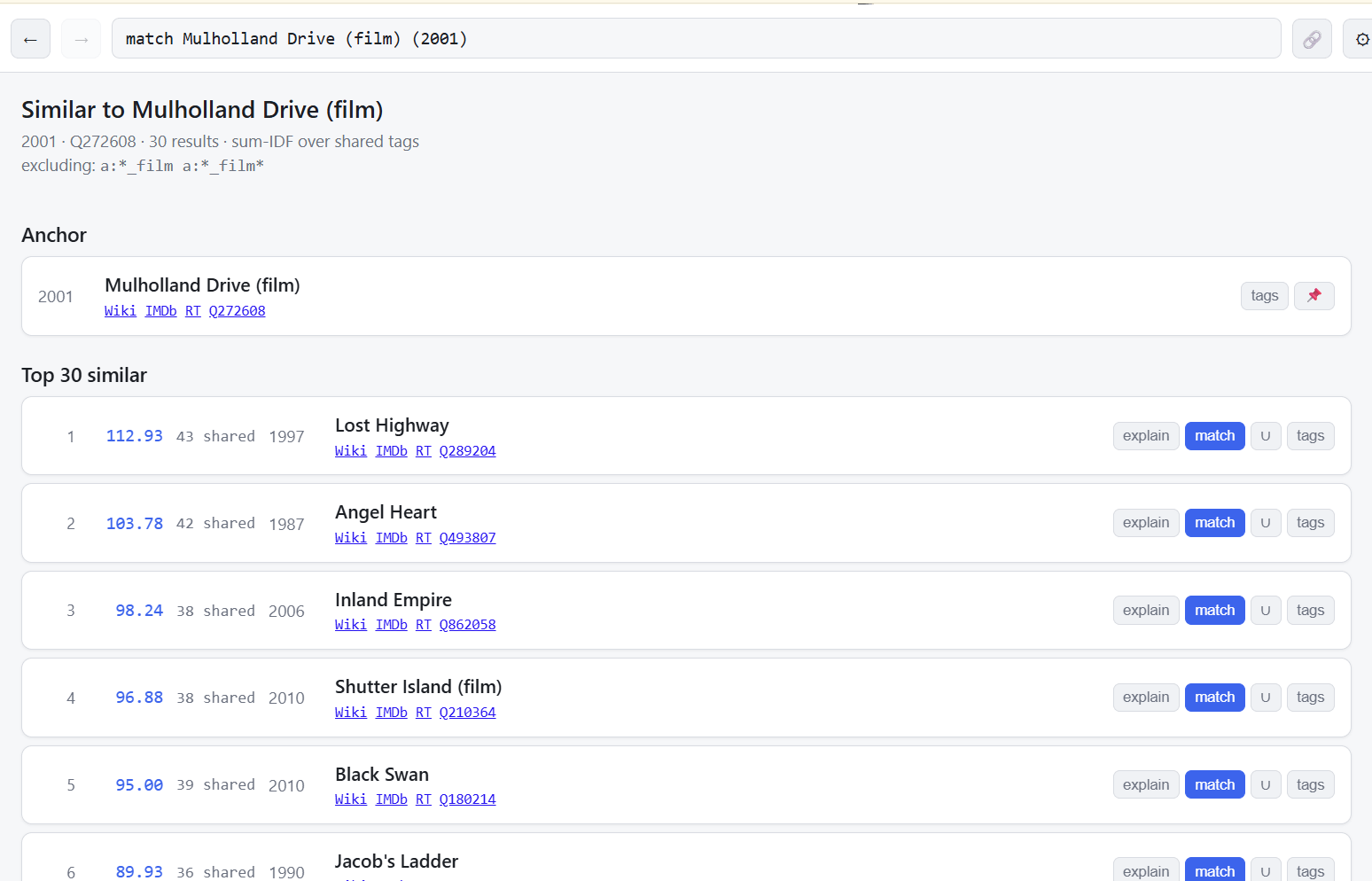
If you want to know why a film matched, click explain.
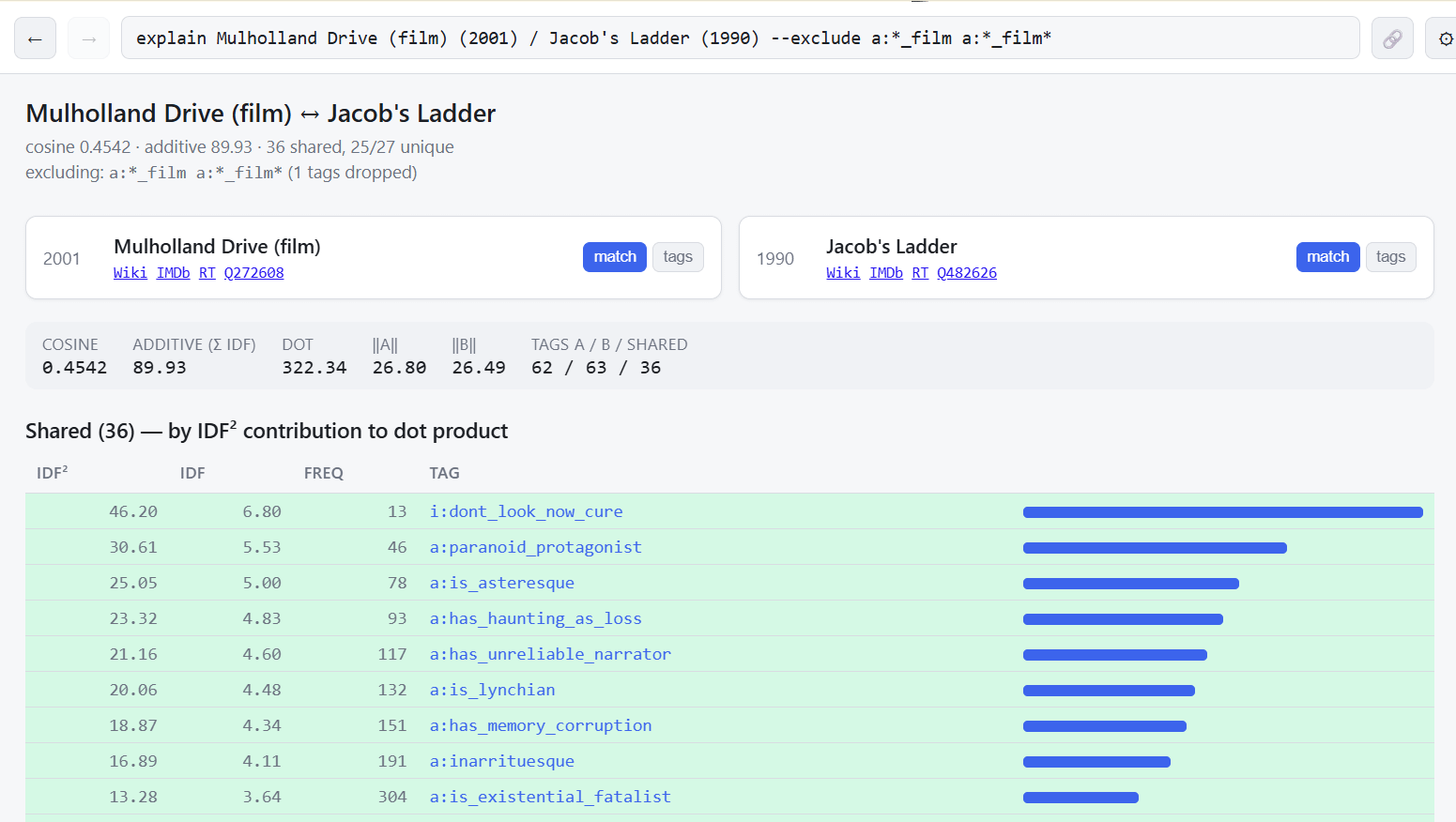
Note that the key to a good recommendation engine that gets you unexpected connections is permissive tagging, that is, in setting your tagging precision rate low enough so that the tags cast wide enough a net to pull in interesting connections but not so wide that they are useless. So if you are looking at this and exclaiming “According to my analysis these are nothing like the films of Ari Aster!” all I can say is you can try to build a tagging system where only 7 films in a 10,000 film set get tagged asteresque, but I think if you think that through you’ll see the problem with that logic.
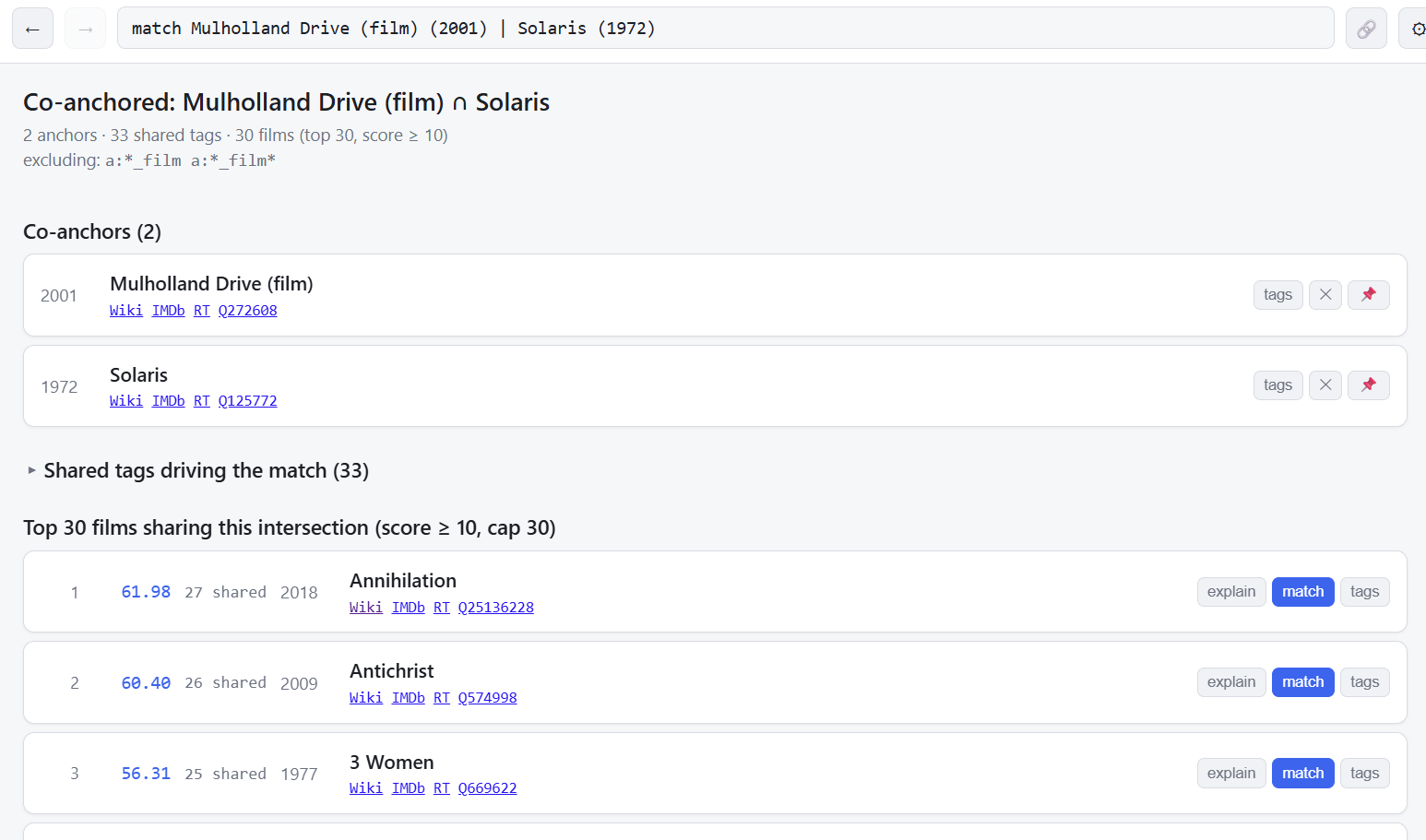
The union function is new, just made this morning, but if you hit the union operator it tries to use two films as “co-anchors” and do similarity based on the intersection of their tags. It’s not quite there yet, but it’s already interesting. Click the little union button in the results. Here we union Solaris with Mulholland Drive, and get a good result set for that I think.
The clustering doesn’t work quite yet, but will cluster films in the list according to intra-list similarity when done.
If you need help, just type help.
At some future point I’ll be open to suggestions or criticisms, but right now questions like “why aren’t there' more films like X in there” or “how come Y is matched with Z I don’t like that” will probably earn you my annoyance if you treat this like a product to which you have some form of user demand. On the other hand, noting interesting patterns (even if those are suboptimal) will garner my interest. In other words, when you use this thing you’re eating a meal in my home, not a restaurant, so please act accordingly and don’t make me regret putting my personal project up.
Also the JSON file represents over a month of work on my personal time to tag it. While legally you could probably steal it, I’d appreciate if you asked before grabbing it for your own project. Not only do I get paid zero dollars to do this, but I don’t even currently have a job that rewards research, so my decision to put it up really is mostly I want to help people get more into films. Looking at it to see how it works of course is fine.
Oh, and per the subtitle — yes, this recommendation engine is just HTML. No server side processing, no run-time AI. Just a 5MB json and bunch of HTML processing 10,000 records and doing similarity computations.
Nice work! I've shared a workshop and presentation called "Discovering Useful Ideas" or "Discovering Good Ideas" for years and this makes me think of it:
https://wiki.wesfryer.com/Home/handouts/ideas
Using algorithms we create ourselves to help with the serendipitous (yet intentional) discovery of great content is not only fun, I think it's valuable from civics and pedagogical perspectives.
I look forward to learning more about how you created https://plot.fyi !
This is incredible. Great work. It gives me feelings of how the internet was when it was people with their own little corner on the web, making their own cool things just because they could. Thank you so much for sharing.