My Surprisingly Effective Follow-Ups File
I've been holding back on sharing this until I could present this more fully, but let's YOLO it.

I’ve been working on a set of moves recently to help average people up their LLM game. The idea is to come up with simple habits that can be applied somewhat mechanistically to get “30 seconds smarter” about things. In my mind there is a big unmet need between people writing long well thought-out prompts and people descending into arguing with LLMs (or not following up at all).
The new approach will serve that need by showing a method that can be taught to students to make them substantially better at prompting without doing the whole context-engineering thing. (Yep, echoes of the SIFT philosophy of simple things to do).
This is not the post introducing that approach.
This is the post where I somewhat wearily realize I keep putting off that post, which means I never introduce a core part of it — my Surprisingly Effective Follow-Ups File. And I give it all to you to play with, while I find time to write a post showing you how to use it effectively.
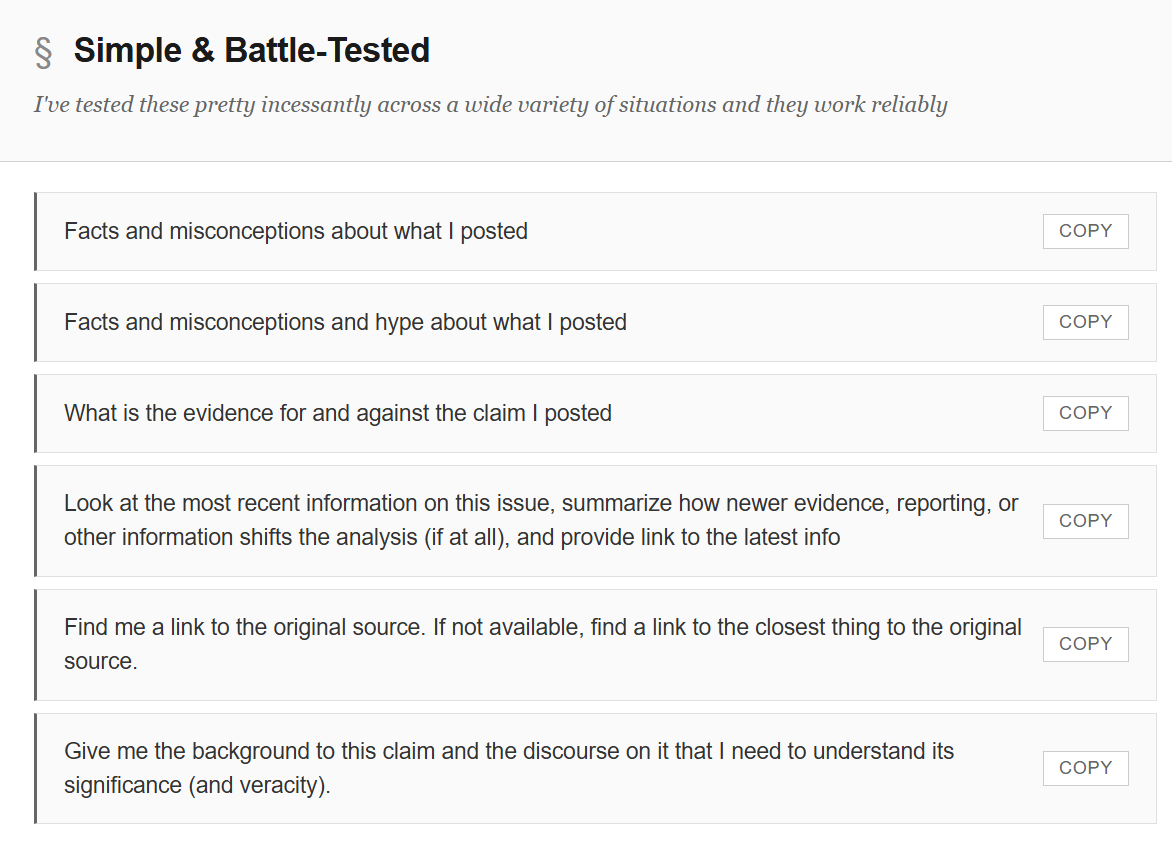
Larger posts more framework focused within a few weeks on this, I promise.
This is GOLD; thank you!
Great tips! As a crazy heavy AI user, it’s an ingrained part of my workflow to have a second context (often using another model) critique the answers given by the first model. I’d say it’s not just good practice but required practice!
To start: LLMs are great at role playing so use that. “What would X say in rebuttal to this” or “grade this argument as if you’re the philosopher Y”. Encourage them to make citations. GPT 5 Thinking is particularly good at researching with citations.
Flipside: LLMs pick up on tone so if you start with “tell me why this is bullshit” you will get answers skewed towards the negative. Neutral questions like the ones you’ve shown here work best. “Weigh the evidence” etc.
However you can get super interesting results by getting that second or third opinion. You can run as many rounds of this as you want. For example: have two different contexts make cases for or against (“imagine you’re in the Oxford debating club and your argument is …”) then have a third context adjudicate the result.
Or you can go nuts and put another layer in that independently fact checks each argument beforehand.
The vast majority of people aren’t pushing LLMs *anywhere near* hard enough! My partner is writing a book and she routinely pastes whole chapters into different models to synthesize different perspectives. I think this is the rest of the iceberg people sometimes miss with this technology.