Why the "Everything is Hallucination" Argument Makes Me Roll My Eyes
From LLMs to the Gulf of Tonkin, distinctions matter. Also: a note about "radar clutter".

Sometimes when talking about a particular LLM misfire people will point out that “everything LLMs do is hallucination” in the sense that an LLM system produces bullshit in the same way and through the same methods as it produces true presentations of facts. This is portrayed as different from what a person does in that the process by which a person bullshits is different from one where they are careful with the truth.
This isn’t a bad observation, and it’s a corrective to people that intuit a human-like intelligence beneath or behind the responses of an LLM. But the idea that “everything is hallucination” only takes one so far, and people that quote it as a way to end a conversation about whether something was a hallucination or not are not helpful discourse participants.
An analogy might help. There are many things that are unique about LLMs but I think we also exaggerate the difference of this technology from what came before. Consider radar. A radar sends out radio waves, when they hit something those waves scatter and some portion of them are statistically likely to bounce back to a receiver. The time it takes for them to bounce back when combined with other information indicates that there is a vessel, airplane, or other large mass out there and can roughly place its direction, altitude, and distance from the radar instruments.
On the night of August 4, 1964, for reasons I won’t go into here, the U.S. Navy was on edge in the Gulf of Tonkin near Vietnam, when they started to see what looked like attacking ships on radar. They fired in defense as the ships on the screen seemed to blip in and out in waves and for nearly two hours. The battle ended without any direct visual confirmation of the enemy, and no enemy craft were ever seen in subsequent aerial reconnaissance.
At 1:27 a.m. local time the next day the patrol’s commander, Captain John J. Herrick, cabled the Seventh Fleet and Washington that many of the “contacts and torpedoes fired appear doubtful,” attributing them to weather-induced radar clutter and “overeager sonarmen,” and recommending a “complete evaluation before any further action.” Subsequent historical analyses and declassified NSA studies confirm that no North-Vietnamese boats were present and the “second” Gulf of Tonkin attack never occurred.
What was the problem here? It’s not fully clear, but the best guesses are that the choppy waves of that night were scattering and bouncing back some of the radar signal, creating the “phantom” ships on screen. Out of these waves and the U.S. Navy’s own activity the appearance of an engaged battle temporarily emerged.
This event led to (or was used as the justification for, at least) a war that would lead to the deaths of 60,000 American soldiers. On the Vietnamese side, the total dead may have been as high as three million, and our attacks on Cambodia killed tens of thousands there and led to the destabilization of that country which killed many more.
As hallucinations and phantoms go, these were some of the most consequential in history. Now consider this response to this historical tragedy. Someone says “They turned out to be phantom signals, there was no real attack.” And someone replies, sagely, “Actually, all radar signals are phantoms, the system was just doing what it always does.”
Does that make any sense? Any sense at all?
In one way this is true, but it’s also quite meaningless. We know there aren’t little planes and boats living inside the screen when it is being monitored. We know that we the readers of that screen turn that into meaning, saying “This is moving like a ship”, “this is higher up and a plane”, “this is likely a land mass and this is seagulls”. But we also know that through a chain of (in this case physical) probabilities a blip moving on that screen in a certain way is highly likely to indicate that there is a corresponding ship or plane out there in reality.
If we talk about certain phenomena as “phantom ships” what we’re saying is in this case a fairly good connection where something on our screen predicted the existence of something in reality broke down, and what we saw on the screen did not have a the expected corollary on the sea.
We know that conceptual difference is meaningful because it matters to us when we hear it. Again, the a person responding to command on the question of whether they were phantom ships who says “It’s radar, General — they are all just sound wave probabilities producing light patterns on a screen, none of it has any inherent meaning” would not have their position long (at least one would hope) and would not be saying anything particularly enlightening. The meaning may not be “inherent”, but it does have meaning because usually when you see something of a certain size moving on the screen in a certain way it corresponds to a ship in reality, and that correspondence is frequent enough and useful enough that we have a name for when that correspondence falls apart, whether that term is “radar clutter” or “phantoms”.
It’s also meaningful because understanding the distinction is what allows us over time to build hybrid systems that mitigate the issues we want to address. Over time engineers have figured out various ways to reduce “radar clutter” through using combined signals to build better systems that model reality in more helpful ways, suppressing a lot of the noise in the system, and hopefully reducing the number of Tonkin-like events. (Or at least such precipitating events; government lying and human confirmation bias are not solvable with engineering).
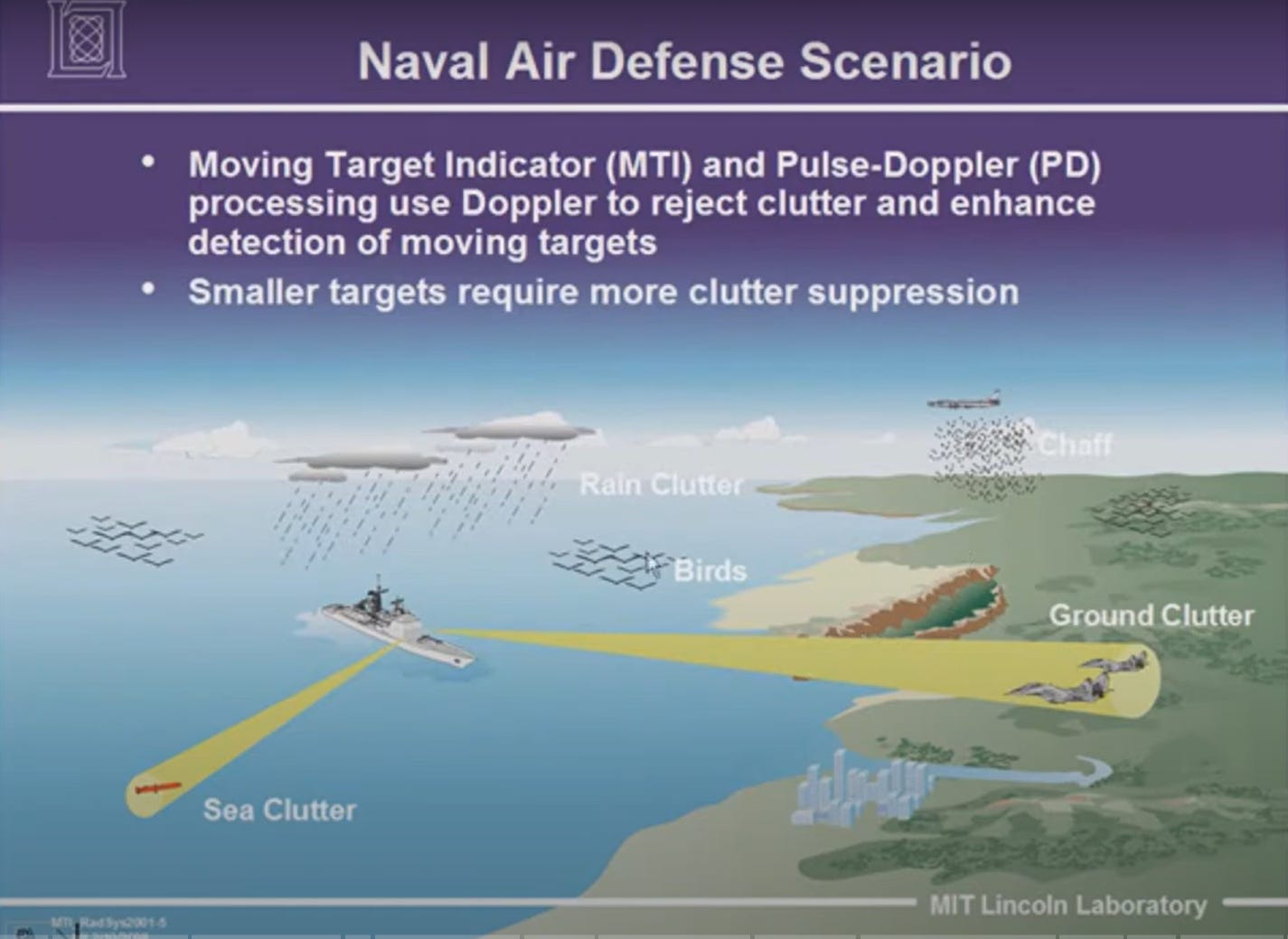
It’s unfortunate that when it comes to LLM’s we’re stuck with the term “hallucination” which implies the system is doing something different when it misfires rather than engaging in the same activity it always does. Like many, I would prefer we ended up with better language here. I think the idea of phantoms is helpful, as is Nate Angell and Anna Mills’s idea of hallucinations as “mirages”. I also think a term that pointed to the likely cause of the phenomenon in a very broad way might be useful. I am a bit taken with the idea of “clutter” from the realm of radar. There seems to be a relevant if not perfect analogy here, where an LLM has a bunch of signal bouncing off of things not signifying any corresponding claims or media in the modeled world.
It’s useful to remind ourselves that the system is never actually “seeing” ships or understanding facts. But the Gulf of Tonkin didn’t mean that “radar was built on a lie” — radar’s ability to model the battle environment remained essential before and after that event. Likewise, LLMs model their source environment, and have an uncanny ability — when recent models “assert” something about things in the real world if you go out and try to find material on the web or in books asserting that same thing it’s usually out there. The blip on the LLM radar has a corresponding set of items beyond the screen. To the extent we use the term “hallucination” it’s because the normal state of the system is one where that connection between the world inside the model and outside the model holds up, which is what makes LLMs so useful and their breakdowns so frustrating.
We absolutely need to use caution when it comes to LLMs, but caution is based on making distinctions. Saying “everything is hallucination” makes a decent point to people who may not already know that. (It’s also annoying to people who do know that, including most researchers who hear the point as sophomores in a dorm room discovering the “we could all be brains in vats” theory).
But saying there is no distinction between a hallucination and normal output makes the same error as those who believe that everything that comes from the model is truth. It confuses distinctions in process with distinctions about the relation of the model output to the world outside it, and ignores that hallucinations — like “radar clutter” — are not random and tend to occur in particular situations that we can be aware of and mitigate through either better technology or better education. The people who address these issues will be the ones who study the unique features of hallucinatory and non-hallucinatory system function, not people who argue the entire distinction is irrelevant.
The scenario you describe is also discussed by Robert McNamara in the Fog of War film. I think part of the argument, whether you call them hallucinations or whatever term you choose, is that some people will say the mistakes make them unusable while others claim they are still useful despite hallucinations.
I had a long dialogue with both Gemini and Claude in my recent testing about the epistemological implications of generative AI and I will admit that it was clarifying for me both in the substance of the responses and in the patterning they demonstrated.
One of the major threads in those conversations concerned the epistemological patterns that derive from the training corpus and from the training feedback provided by developers and users. To wit: the high (and increasing) probability of generative AI responses that have truth value is a reflection of the degree to which the vast expanse of digitized text used for training favors those truths. That's where your radar analogy kicks in, I think: that radar operators get used to "reading" the pings from things that are really, ontologically there, but also understand that the system pings in response to both mechanical and environmental glitches that are not "there" in the same sense.
The difference might be that the only reason the training corpus produces more truthful or accurate information is because the textuality of the 20th Century and early 21st Century overwhelmingly dominates the corpus, and work that is scholarly or at least informed by scholarship in turn dominates that just in terms of pure percentages. Even works of fiction are in many cases shaped by the secular, factual, liberal, rationalist norms of 20th Century expression and thinking.
We're fortunate in some sense that the generative AIs that best simulate human expression require the most comprehensive textuality--it wouldn't have been possible to produce Gemini, Claude or ChatGPT from a corpus just limited to religious texts, to conspiracy theory, to fringe philosophies, to experimental fiction, and so on. If that had been possible, they would "hallucinate" much more both in the sense of struggling to make sense in natural language to queries that weren't posed within those epistemological frames and in producing nonsense or falsehoods that mirrored the narrower corpus.
But this is where the analogy to radar (sort of) breaks, in that it would be harder to become a skilled interpreter of radar signals if the reality of the material world could potentially shift on an ongoing basis, or if the radar designers could "relax" the working physics of the radar in order to detect more ephemeral kinds of material noise in the world. It's enough of a challenge for radar to keep up with the shifting nature of military technologies that are in some cases designed to confuse or evade radar. With generative AI, the character of the training corpora are the only reason that everything the AI says is not a "hallucination"--it's because it is reproducing patterns of language that were not produced as hallucinations in the first place. Which is important--but I fear that a lot of generative AI producers actually don't understand that the improvements they're seeking rest on the maintenance of and continued production of knowledge in digital texts by human beings who are governed by fidelity to accuracy, evidence and truth.