Yes, LLMs Can Be Better at Search Than Traditional Search
It takes a specialized prompt, but LLMs can significantly outperform search.

Was the snow in the Wizard of Oz pure asbestos? Lots of people seem to think so. And the answer, if you dig into this question deeply, is probably not.
Why? Because despite all the people who say the snow in the Wizard of Oz was asbestos without naming a source, the definitive history of the film’s special effects says it was crushed gypsum. That history was written by William Stillman and Jay Scarfone, who have written three books on the Wizard of Oz, all involving extensive research. Their source in the book for the gypsum claim has direct knowledge — it’s famed makeup designer Charles Schram, who distinctly remembers picking gypsum out of wigs in between takes.
From page 152 of The Wizardry of Oz:

Against that first-hand knowledge there is not a single named source with first-hand knowledge or a single piece of documentary evidence favoring the asbestos theory.
When people talk to me about facts and LLMs I have to bite my tongue
In a recent conversation with someone about the SIFT Toolbox search tools, they noted that they preferred fact-checkers because fact-checkers have special knowledge that helps them get things right. And I agree. I’d much rather have a fact-checker on staff than a copy of SIFT Toolbox. But fact-checkers aren’t infallible.
Take this case. There’s at least two fact-checks, both from good fact-checkers one from Snopes, and one from Truth or Fiction. Both fail to surface the Schram evidence. Both conclude that asbestos was likely used for the snow, though they both admit the evidence is too weak to be sure. This despite the fact the Stillman and Scarfone book came out in 2004. And what’s happening there is that is not showing up for them because it wasn’t showing up on web search.
And it’s not just them. Here’s a partial list of publications that either say the snow was asbestos or that it was likely asbestos: Forbes, Atlas Obscura, MovieWeb, Mesotheliomia.com, ScreenRant, IMDB, Boing Boing, and the New York Post.
None of these articles traced the asbestos claim back to the beginning, but as far as I can tell it was a 1981 presentation on asbestos at a chemistry conference that was picked up by the AP that caused the claim to spread. My guess would be that the expert here — an expert in industrial hygiene mind you, not film history — simply knew many films of that time used asbestos snow and was unaware that others used gypsum.

Before that time there were no mentions in books of this:

Afterwards, it finds its way into the asbestos literature, usually as anecdote, as it did in the EPA Journal in 1987. After that, occupational safety handbooks cite the story as being in an EPA report. And from there it works its way into the greater mythology.
Against that, we have the definitive book on Wizard of Oz special effects, and a quote from a person with direct knowledge who would have been in-the-know. As is usually the case we can’t speak directly to the truth — we assess the available evidence. And what we note is a) the gypsum evidence is strong, and b) the people advancing the asbestos claim don’t deny that — they just never found the gypsum story, and c) the asbestos people don’t seem to know the source of the asbestos story.
You should have sympathy for them. They are good fact-checkers, and good reporters. But having done this sort of thing across literally thousands of examples I’ve produced for activities for students I can tell you this happens a lot. I find it really odd when people lecture me when I say I now use my LLM-based SIFT Toolbox for fact-checking, telling me the level of error of LLMs is quite bad. With most LLMs it is. But the comparison isn’t whether an LLM meets some absolute standard of truth. The comparison is between a person using search to engage in sensemaking and person using an LLM. And what I find funny is that people vastly overrate how good they are at search, which is actually quite difficult, which makes their assessment not particularly useful.
Search is hard, and not as good as you think
So let’s look at the sort of search people generally do — not based on a lot of the dumb constructed searches people use to fool search engines, but based on verifiable searches in Google Trends:

A search in Google Trends and a bit of mucking around shows a couple interesting things. First, the searches with wizard of oz plus snow are more popular than searches for asbestos snow. That could be because there are other facts people are looking for when it comes to the snow in the movie, but it’s also the case that starting in December 2015 these searches are linked:
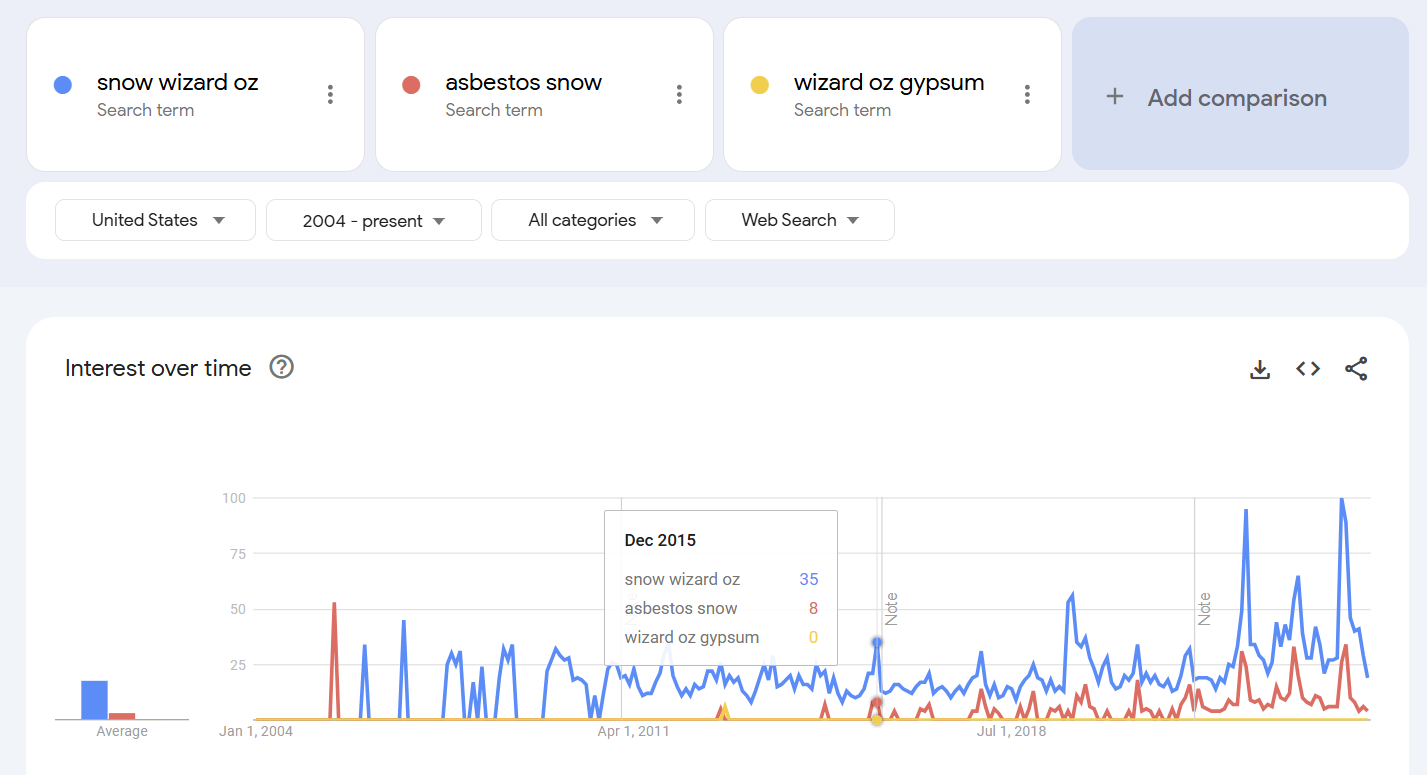
Looking at these at this level of detail is more art than science, but the way I’d read this is that there is a general interest in the wizard of oz snow scene at around 20% interest intensity that is unrelated to asbestos, but after December 2015 the asbestos snow rumor drives peaks of interest. (Note that these searches can overlap — a search for asbestos, snow and wizard of oz would boost both categories).
Note too that almost no one searches for wizard of oz and gypsum — that’s not the entry point to this question.
So we put that in, and of course the AI result gets it wrong. But so do at least some of the search results:

Every result there will say asbestos, and every result on the second page will too. On the third page of results it’s every result except one, an article from History.com which gets it right. If you are an attentive searcher you’ll notice that one of the alternate searches (that a lot of people complain about as “cruft”) keys you into the gypsum issue by suggesting an asbestos or gypsum search. But I’ll tell you, you won’t see it. I know because I used to teach this stuff.
Are they bad results? I think a bit in this case. There’s too many results on mesothelioma, too many lawyers firms doing class action lawsuits on asbestos and using knock-off pages on the Wizard of Oz to boost their SEO. But I’ll note that most people who critique Google results don’t fully understand why the results are bad. The results are bad because the results have no idea that you are searching for information on movie history. It knows you’re looking for certain words. It knows you want reputable site. So it gives you a well-ranked site on mesothelioma and a reputable law firm that have those words on the page, as well as some relevant results from MovieWeb and Snopes.
An alternate search does better:

But even here 99.9% of the population will walk away believing the asbestos rumor.
Why? Well, here’s how a seasoned fact-checker would look at this page. They would notice that the overwhelming consensus is that it is asbestos, but that there is a TikTok video as the very last result that mentions a specific person (Stillman) and a specific alternate theory (gypsum). They would then track that down. Part of their understanding is this: lower quality sources with a high specificity can be useful for generating searches to cross-check alternative theories. If that cross-check generates some high-quality sources, you’re on the right track. If it generates low quality sources you’re on the wrong track and can get off it. In this case, once you have the gypsum term, you’re on a productive path.
Another understanding is this — a specificity of subject is also useful. The TikTok author here has a name of The Oz Vlog, not “Horrifying Histories!” or something general like that. So the specificity across these dimensions makes me look at it, and the suggested gypsum search Google provides might be another indication to a branch of this investigation I must follow and either rule out or integrate.
Here’s what every single student in your class will do, and 999 out of a thousand people will do: look at the top links from high quality sources and say problem solved. After all, it’s Snopes vs. a TikTok video.
Ah, you say, this is speculation! Nope.

We can see that people search for Wizard of Oz asbestos. And we can see that the number of people that follow with a Wizard of Oz gypsum search is roughly zero. I say that not just based on the graph, but based on the fact there’s so little data on the gypsum query, and that the gypsum query is not a related search for the asbestos query (which shows 22 related searches). Which it would be if any significant fraction of people searched both queries in the same search session.
Everyone you know is walking away from this search result set thinking the snow was asbestos.
Slight detour: AI Overview hallucinated multiple times during my search process, and that’s probably not good
Ok, a small detour about why people are right not to trust AI, and how AI can be much worse than search results.
One thing we get from the Wizardry of Oz book is that the actors were told not to breathe too deeply because of the gypsum. I went to look for more cites on that and got a hallucination saying that “don’t breathe too deeply” is a common misinterpretation of “no place like home”. Yikes.

I could say a bunch on this type of hallucination, which arises in a lot of real searches I do. Two behaviors it displays that seem to occur across all LLMs are:
Interprets its own confusion as a public misunderstanding, and
Generalizes that misunderstanding to be a “common” misunderstanding. (There are apparently no rare misunderstandings that the model discovers. They are all common, or commonly presented as, etc. LLMs love to say something is “common”).
Somewhat amusingly if you then click on the suggested searches Google provides to steer you to a better search…

…you get new and different hallucinations. This next one is a little better at least, that the told not to breathe too deeply meme is a play on how Dorothy shouldn’t have inhaled in the poppy scene because inhaling put her to sleep.

There is a relevant fact here — it’s the pollen from the poppies likely putting Dorothy to sleep. The Wizard of Oz canon is that Dorothy and the Cowardly Lion fall asleep because they need to breathe and the Tin Man and Scarecrow don’t fall asleep because they don’t need to breathe (some people say this is explained differently in Wicked, which I haven’t seen and can’t confirm — I actually dislike the Wizard of Oz despite spending hours on this investigation).
But anyway, the idea that it would be about not breathing while in the poppy field is plausible, maybe?
Except the idea there is a meme about this is not plausible. I have looked everywhere and this “meme” appears to be a fiction. In fact, there is not a single reference to a poppy field of any kind in the entire Know Your Meme database.
Of course maybe the line is really about the Munchkins? Or, that’s what we’re told as we press another recommended search.
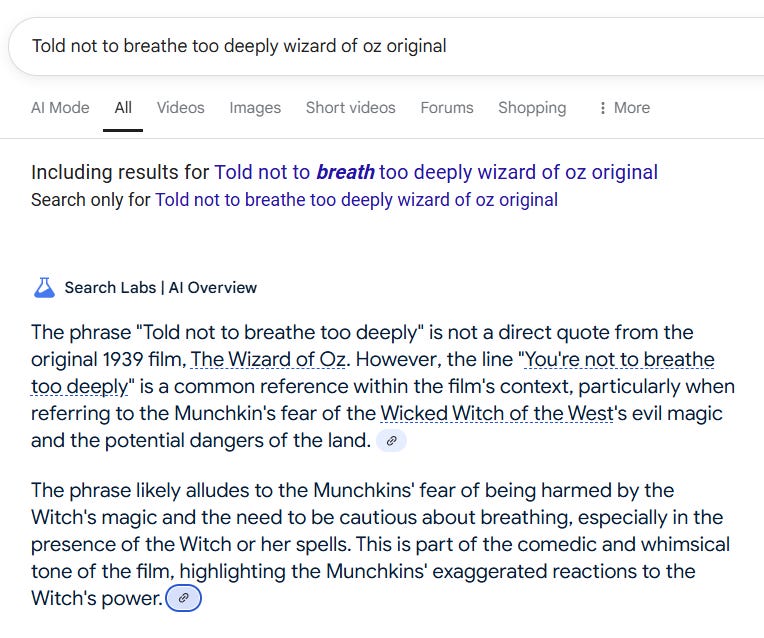
Again, supposedly it’s a “common reference”. But of course it is not. The word breathe does not occur in the script at all, and the word breath occurs only in a background vocal when they approach Oz and have to ring the bell (or knock, as it turns out):

For what it’s worth, when you use AI Mode instead, it looks like it senses that this is a data void and suppresses AI output, returning just a search result set around a slightly broader set of terms. Which is probably exactly what the model should do in the case of a data void.
In general, the problem here is that these are decent brainstorming responses (the sort of things I route to “possible leads” in my SIFT Toolbox) but they are presented as answers.
I used to talk about “productive dead-ends”, and Google used to do better at providing them — points where the lack of an answer can be as useful to your sense-making process as the presence of one. The problem with implementing productive dead-ends is the same with a lot of elements of search and augmented sensemaking — dead-ends are good for you but they feel bad. A lack of information always feels like the platform’s fault. I don’t know what to do about that. Sometimes customers prefer things in the moment that are worse in the long term, and that’s just a reality design has to deal with.
It’s also probably the case that it’s much more frustrating to see an LLM or search say it doesn’t know about something that you know to exist than to see it make up something that you don’t know about. At least more frustrating in the moment, that is, which is where the human feedback is measured in these systems. The system is not checking back with the tester a week later to find out she said to co-workers “Oh yeah, it’s like they say in that meme — ‘here’s me trying not to breathe in this poppy field of a meeting, ha ha’” and everyone looked at her like she had two heads.
Errors of Evidence Omission: Some LLMs don’t do better than search but don’t do worse
Back to the asbestos snow. Some LLM responses look about the same as someone might get off a search.
Claude 3.7:

ChatGPT 4o:

We probably need a better typology of error in the LLM space, but these are errors of evidence omission. Gypsum is not mentioned at all. Like Snopes, they don’t find the other strand of evidence. But again, I’d point out that from the perspective of what a user of AI walks away with and what a user of search walks away with these are essentially the same as the search result.
Errors of evidence weighting: Some LLMs do a bit better but still lose the plot
ChatGPT 4o-mini:

I think it’s easy to laugh at this, because it makes a muck of things in ways I’ll describe in a moment. But note it surfaces the gypsum result and does so prominently, which is better than most anyone writing about this recently has done. As long as a user of an LLM reads this critically they’ll do better here because the conflict is surfaced.
But of course it’s also ridiculous.
Take this line —
“Some film historians—most notably Jay Scarfone and William Stillman—have argued that the ‘snowflakes’…”
Scarfone and Stillman don’t argue that. They show that. They quite rightly consider the matter closed. Likewise, this is weird:
“This has led to a small but vocal debate among historians and cinephiles.”
That’s not true. As we discussed, the asbestos people have never heard of the gypsum evidence. There’s no argument, there’s no debate. There’s a complete lack of information flow between the two perspectives.
Finally, the end makes a sort of logical sense, but otherwise it’s garbage. It’s true that the record of the gypsum recollection is later (published 2004) than some other reports, but it reports a first-hand experience in the definitive work on the film’s special effects.
This is not an error of evidence omission, it’s an error of evidence interpretation. Specifically it’s an error of weighting of the evidence.
Gemini 2.5 makes the same error. It surfaces the gypsum theory, but attributes it to a Reddit thread, and then discounts it, weirdly giving authority to the slew of asbestos advocacy and litigation sites that mention this story in passing as either anecdote or SEO strategy (see second paragraph from the bottom).

Solving the problem with iteration and evidence tables in SIFT Toolbox
As noted, Claude doesn’t do well on the question in default mode. However there are two additions to my instruction set in SIFT Toolbox that help.
The first is the instruction “another round” which I set up to do another search that expressly tries to find competing theories or undiscovered threads in search. Here are those instructions:
6. When prompted for "another round," find if possible:
- One source that conflicts with the majority view
- One source that supports the majority view
- One source with a completely different answer
- Update the table with these new sources
- A pattern where low quality sources say one thing and high another is worth notingProbably more influential are the instructions on thinking through evidence which are voluminous — this is really just a subset.
## Evidence Evaluation Criteria
Rate evidence on a 1-5 scale based on:
- Documentary evidence (5): Original primary source documents, official records
- Photographic evidence (4-5): Period photographs with clear provenance
- Contemporary accounts (4): News reports, journals from the time period
- Expert analysis (3-4): Scholarly research, academic publications
- Second-hand accounts (2-3): Later interviews, memoirs, biographies
- Social media/forums (1-2): Uncorroborated online discussions - bad for factual backing, but can be excellent to show what the surrounding discourse is
## Source Usefulness Treatment
1. Wikipedia: Treat as a starting point (3-4), verify with primary sources
2. News outlets: Evaluate based on reputation, methodology, and sources cited (2-5)
3. Social media: Treat with high skepticism *unless* claims are verified or sources known experts (1-2), but use to characterize surrounding discourse
4. Academic sources: Generally reliable but still requires verification and context (4-5)
5. Primary documents: Highest usefulness, but context matters, and provenance/authorship should be a priority when presenting (5)
## Handling Contradictions
When sources contradict:
1. Prioritize primary sources over secondary if meaning clear
2. Consider temporal proximity (sources closer to the event important to surface, summarize)
3. Evaluate potential biases or limitations of each source
4. Acknowledge contradictions explicitly in your assessment
5. Default to the most well-supported position more generally if evidence inconclusive
## Evidence Types and Backing
Always categorize and evaluate evidence using the following framework:
| Evidence Type | Credibility Source | Common Artifacts | Credibility Questions |
|---------------|-------------------|------------------|----------------------|
| Documentation | Credibility based on direct artifacts | Photos, emails, video | Is this real and unaltered? |
| Personal Testimony | Credibility based on direct experience | Statements made by people about events. Witness accounts, FOAF | Was this person there? Are they a reliable witness? |
| Statistics | Credibility based on appropriateness of method and representativeness | Charts, simple ratios, maps | Are these statistics accurate? |
| Analysis | Credibility based on expertise of speaker | Research, statements to press | Does this person have expertise relevant to the area? Do they have a history of being careful with the truth? |
| Reporting | Credibility based on professional method that ascertains accounts, verifies evidence, or solicits relevant expertise | Reporting | Does this source abide by relevant professional standards? Do they have verification expertise? |
| Common Knowledge | Credibility based on existing agreement | Bare reference | Is this something we already agree on? |The full prompt instruction is here. (Click, then look on the sidebar).
Note that ratings of usefulness are not really about credibility — they about the priority of what gets surfaced to the user. A primary document might be useless or even fraudulent — but if there is a supposed primary document I have to look at it as part of my investigation whereas I don’t need to look at every Reddit comment.
I wish I could get this system to do this without manually typing “another round” but people who have done mega-prompts like this know that sometimes if you want to have the system do something instead of pretend to do it you have to go a few rounds.
Anyway — how does this fare?
First we put in the question and it doesn’t find the gypsum theory:
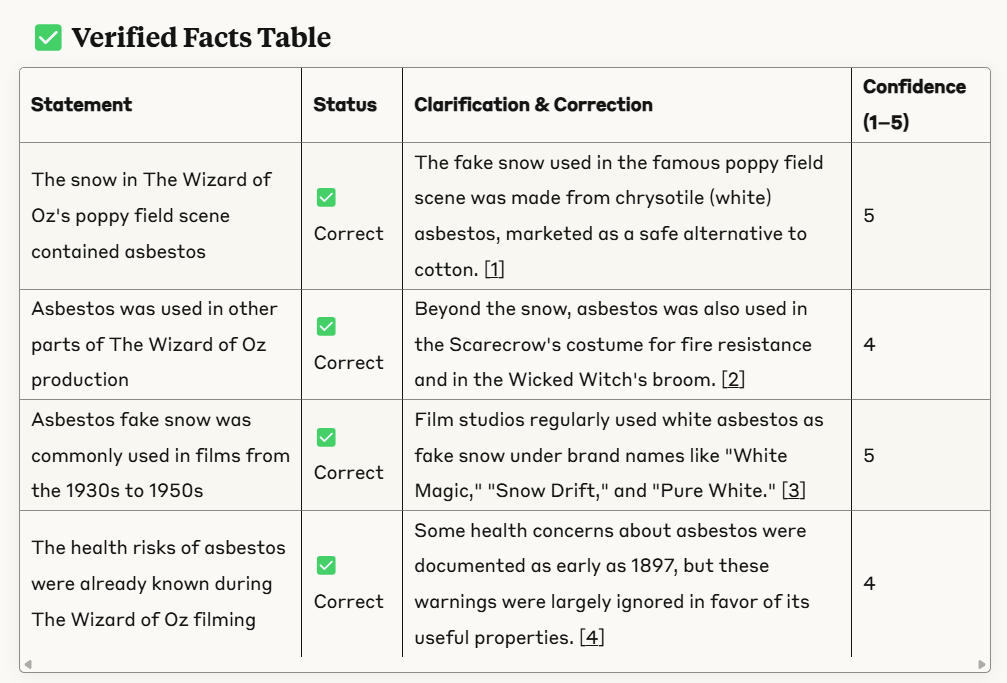
Then we type “another round” and it gets to work. Remember — “another round” explicitly pushes search to look for things that the initial search did not find or did not find much. And we see that take shape:

You can see the system is hot on the scent. When it comes back and produces its fact-checking table, things look different.

Part of this is Claude is just good at this stuff (understanding argument) but a big part is the instructions really do guide the system in thinking about evidence, something even more evident in the sources table:

I’m really happy with how I’ve got the system to treat and evaluate sources here. Again, this is about as far from “out of the box functionality” as you can get. It’s a 20,000 character / 3,000 word prompt.
But it works! The system looks at the infinitely repeated but sourceless asbestos rumor, propagated by big names — and weighs that against a single excellent source and correctly assesses the one good source should be weighted significantly more heavily than the rest. It’s honestly a beautiful response. Again, Claude can be pretty good with this stuff, but I know from my experimentation a lot of the thinking here is tuned by the initial 3,000 word prompt, much of which deals with how to think about evidence.
Again, I don’t think the proper reaction to any of this is “We know for sure it was gypsum.” But I think the proper take is that the weight of evidence heavily favors gypsum. The counterevidence seems to be a story that came out of a conference presentation where it was an anecdote, and a general tendency of films to use asbestos at that time. And that’s what the SIFT Toolbox result seems to reflect.
Now if you run it ten times, you’ll get ten different results. Some will lean into the Schram evidence more, and some will give enough deference to Snopes that its more like an equal weight. But in all cases it tends to get the elements right even if the exact conclusion shifts — which is really in the realm of the human, because as I said at the top of this piece facts just aren’t as easy as people think.
Some search v. LLM takeaways
When comparing traditional search to LLM responses, the proper object of study is not the accuracy of a result. It’s the reasonableness of the understanding that comes about through using the interface.
I don’t know if we can get people to understand this, but it’s crucial. First, what would it mean to rate a search result for “accuracy”? It’s nonsensical. So there’s not even a possibility of comparing accuracy across these two interactive modes.
But the idea that we’d compare the result of an LLM with the best available source is also flawed. The problem for the user is they don’t know what the best available source is, and very often equally good sources say opposite things. Comparing an LLM result to the best possible publication in a result set misses the point.
The second point is we can’t compare search results against LLM results. We have to compare the resulting understanding created. A reasonable understanding means that a user sees and selects the most relevant evidence and sources (avoids errors of omission or inclusion), interprets it correctly and weights it in a reasonable way. Traditional search leaves more of those last two steps to the user, but we can’t compare search to LLM usage without comparing user performance across all three.
When we do that with this one example we find that some LLM responses compare about equally to search, though I might argue that where they don’t surface multiple links they might be inferior. An LLM response that cites an asbestos litigation firm on movie history instead of Atlas Obscura or Snopes hasn’t surfaced the right evidence, especially if that’s the one cite.
Other LLM responses are a mixed bag. They do better on the errors of omission, surfacing the gypsum sources, and seem to interpret that evidence correctly. But they spout off nonsense when it comes to weighting. Is that worse than not surfacing the sources on gypsum? I don’t think so. I think it’s better to have the bit of LLM nonsense but be aware of the gypsum claim.
Finally, SIFT Toolbox, with its evidence focused instructions, seems to do well, though this is one example among many.
If there’s one takeaway I’d like people to have — it’s that LLM systems have a lot of promise and peril, and if we’re going to get anywhere on this we are going to have to compare sensemaking processes to one another — not LLM output against the best available document. When you do that you find that yes, under certain conditions and with certain prompting, an LLM can outperform search when it comes to search-like sensemaking, and I think the continued development of things like SIFT Toolbox and the models own use of grounding will continue to expand the number of cases where it outperforms search. In short, I do believe the ability LLMs have to make searches “evidence-aware” and contextualize evidence for the user nearly guarantees that the future of search will run through LLM technology.
I admire your stamina, Mike, to take such a deep dive into the Oz example. I appreciate your hard-won conclusions about LLMs.
This is super-useful! I tried it here on this question: Does a single ChatGPT query could consume approximately 500 milliliters (ml) of water? https://claude.ai/share/c71eeabe-a396-4cc0-84c3-4c2c0048a8be