Hallucination Chains
AI searches citing Grok hallucinations is not the future we want

One of the most common baiting methods on the internet is taking a famous but not too famous film, posting a scene from it, and asking (as if you don’t know the name of the film you just ripped, cut, and posted) if anyone knows where the scene is from. This is how people make money in year of our lord 2025, creating little opportunities for people online to show how smart they are while the poster rakes in the clout.

The game has changed a bit though because now people in the comments just ask Grok — though with not always great results:
")
Even if you don’t know this movie is King of New York and it’s from 1990, you probably know that Christopher Walken does not look like this in 2025.
I got curious though about Grok’s mistake. It seemed a weird misread of the title of the film. King of Newark 3 exists, and has (as noted) similar themes but I’m not sure that Newark is known for a robust subway system. Was this a legitimate misread based on a similar subway scene, or (as was more likely) a hallucination1 produced by trying to justify a movie name misfire?
So I Googled to see if King of Newark 3 (an indie film with such a small following that there is no Rotten Tomatoes page on it) had a subway scene. And the answer I got was not great.
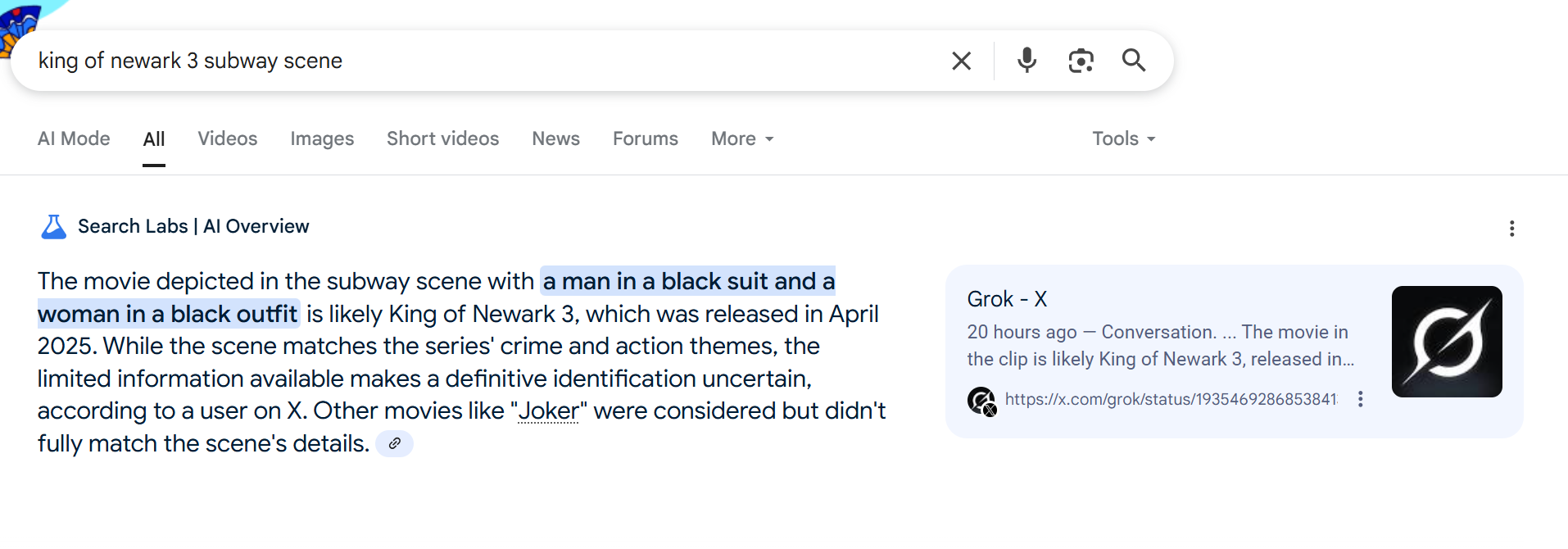
Citing Grok, AI Overview does a very light rewrite of the Grok response. Unfortunately, so did AI Mode:

I’m not a believer in the whole AI synthetic collapse thing, but I think there’s plenty of examples that while not full collapse can make the internet suck more. This pattern has probably been named by someone else already, but because it’s my day off and I’m feeling lazy I’ll call it “Hallucination Chains”. We should really try to avoid it.
I’m picky about what I deem a hallucination and what I don’t, but I think in this case it is probably a hallucination — there is no real-time search information on this movie about a subway scene in King of Newark 3, the name issue is really obvious, it seems like a made up post-hoc rationalization not grounded in any part of the dataset (either model or real-time). Also, I don’t love the term hallucination, but that’s where we seem to have landed so that’s what I make do with.
"Collapse" might be a strong word but there are two aspects of hallucination chains that really do seem to portend that possibility. The one is that the kind of chain you described in the post is essentially fully automated--those chains can form without any human being involved in the process. (Even the "internet bait" query that kicked it off is substantially fueled by bots on Reddit at the moment.) Generative AI trainers can make some interventions if and when that looping starts to get out of control, but the scale of this behavior is so potentially huge and rapid that I could see it being almost impossible to interrupt if it's left alone too long.
I think the more pressing problem is that the info-slop that hallucination chains could generate at large scales is also a serious disincentive to human beings who create higher quality information in various forms, especially in repositories like Wikipedia that generative AI RAGs and deep -research lookups dependent upon. If human information and knowledge producers simply pull out of those kinds of spaces and retreat into much more siloed and firewalled archives where they're being paid for the value of what they contribute and where there's some protection from slop, that could lead to a really rapid collapse of the kinds of information that wider publics presently expect to find online.
This is just automated citogenesis https://xkcd.com/978/