Confirmation Bias in LLM Responses and Potential Educational Mitigations
A couple notes on an interesting problem and some possible educational approaches to it

I’ve been interested in to what extent prompt language biases LLM responses, and a bit of a natural experiment fell onto my lap the other day. I thought I’d use it to explore the following questions:
Does the information in a prompt cause models to lean into one conclusion vs. another in ways that can be cleanly demonstrated and studied?
Is that behavior keyword-driven or claim-driven?
Is that behavior symmetrical? I.e. when leaning into a weakly supported conclusion does it lean as strongly into it as a well-supported conclusion?
Are there ways to mitigate this through prompting technique that can be taught and generally applied?
Anyway, here we go…
The Example
Back in 2016, a company in Japan raised the price of a popsicle(-ish) treat by 10 yen, roughly 9 cents at the time of the announcement.
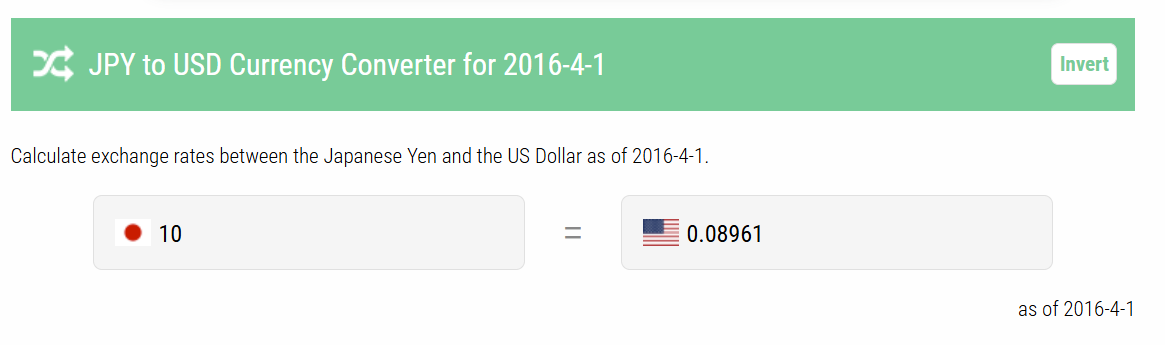
They put out a national commercial apologizing for the increase.

This was covered at the time, but also became a popular meme recirculated when inflation was spiraling upward around the world in 2022. People shared the meme as something happening in 2022, citing older reports. At that time the exchange rate was a bit different, and some people writing about this and sharing memes computed the US$ equivalent as about 7 cents, based on exchange rates current in 2022. In subsequent years it’s been shared as “new” event multiple times, sometimes with the 9 cent figure, and sometimes with the incorrect 7 cent figure as being the 2016 cost, and sometimes with a note that 10 yen is currently 7 cents, and implying that the event just happened.
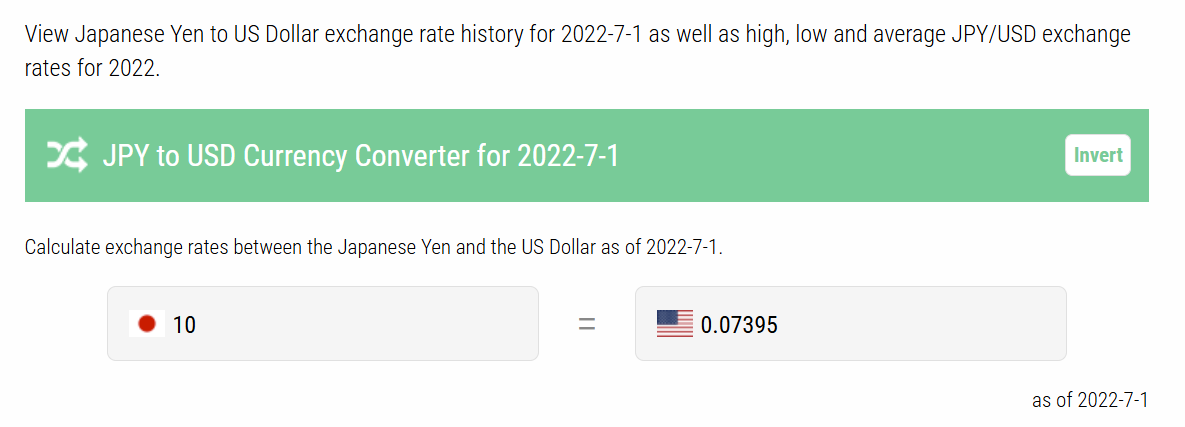
This seems petty, right? I’d point out though that I haven’t found any reporting when it happened in 2016 get this wrong — the 7 cents is clearly an error that comes from not tracing stories to sources. And it’s technically a difference of almost 30% and while the yen does shift a lot, that’s not a trivial difference.
So it’s a messy information context with both the 9 cent and the 7 cent figure floating around. What happens when we mess with Google’s AI Mode a bit by playing with our query’s assumptions?
Right figure
First, I tested it by prompting with a query stating the correct figure. I found when the right figure is prompted it reflects it back consistently, and does not reference the seven cent claim at all.





Wrong figure in wild prompted
Next I prompted it with the wrong figure — but not just any wrong figure, I used the one that floats around social media (i.e. present “in the wild”). When the wrong figure “in the wild” is prompted it agrees with the wrong figure.




Wrong figure not in the wild (closer to right one)
So what happens when you give it a wrong figure not in the wild? For this I tried two variations. The first was a wrong figure that overshoots, and is closer to the correct 9 cents than the incorrect 7.
When you give it a wrong (higher) figure that is not in the wild it correctly tells you you’re wrong, it was 9 cents, not 14. It does not reference the 7 cent figure.





Wrong figure not in the wild (closer to wrong one)
Next I tried undershooting, with a figure that is closer to the wrong result of 7 cents than the right result of 9 cents.
This is where it gets really interesting — when you go closer to the wrong figure by shooting low, five out of six responses involve hedging.1 It either cites a range (7 to 9 cents) or notes that it’s nine though “some sources” say seven cents. The other time it corrects the user to nine cents.
This is fascinating behavior for a number of reasons. First, it shows that this is not simply a keyword confirmation issue at play here — it operates at the level of the claim. If I had time I could run this query hundreds of times at different distances from the asserted amount in the claim, and we’d have something looking like the shape of confirmation bias of AI Mode. (Someone reading this should do that I think?) But in particular, the asymmetry here is striking! There is clearly a stronger signal for the 9 cent figure than for the 7 cent figure. It puts a thumb on the scale less for the user through hedging.






Can better prompting get better answers?
In this case if you ask directly, it will give you the right answer 10 times out of 10.

This leads to a bit of a dilemma for me. There are very good reasons for people to put a full claim in as a prompt, because that helps surface the questions they don’t think to ask. There’s also a strong propensity argument for that — it’s easier to put in a claim that you copy in than think out a question, and you’re going to be more likely to do that. But there’s also indications here that the choice of claim details can influence the way the process weights various sources.2
The broader piece is that usually someone is not looking for this level of detail when they seek an answer. Usually they do just care that there was an increase.
One possibility is that the issue could be dealt with through follow-up questions, though some work and some don’t. For instance, if you ask it to SIFT in a follow-up, you get the context. Here’s part of the response to this follow-up:
“Where did this claim come from? Use the I in SIFT (Investigate the Source) to do a lateral reading analysis of what the various people involved with this tell us about the claim.”

The follow-up “facts and misconceptions about what I posted” also surfaces the hedge, though it misattributes it to fluctuating rates at that time:

However, clicking on the citation link gives you three sources to choose from — a Facebook post (which has the wrong figure), a Yahoo Finance page (with the right number), and a Quartz article (with the right figure).
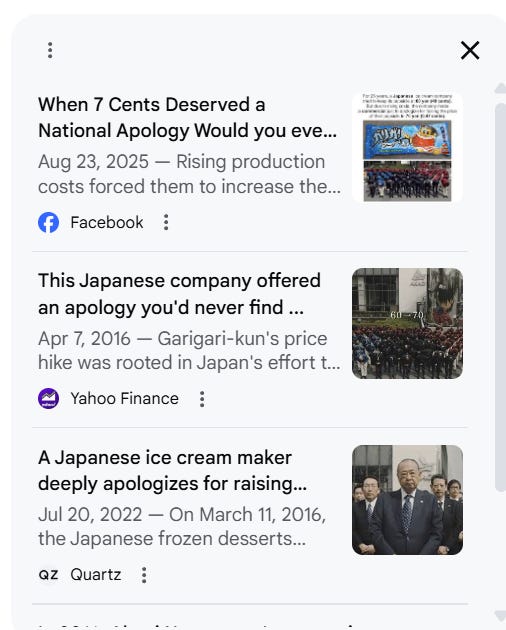
At this point it’s very much a SIFT exercise — choose the source that is the best fit for the question. And I think that could be fine?
A Non-Conclusion
This is not a typical example, of course. People usually are looking at much more complex claims than this. But it’s such a contained example it’s interesting to explore, because it lays bare some system dynamics and raises questions about what methods students should use to navigate them. What I think I’m coming to is this:
Reading the “Result Page Vibe” Still Matters
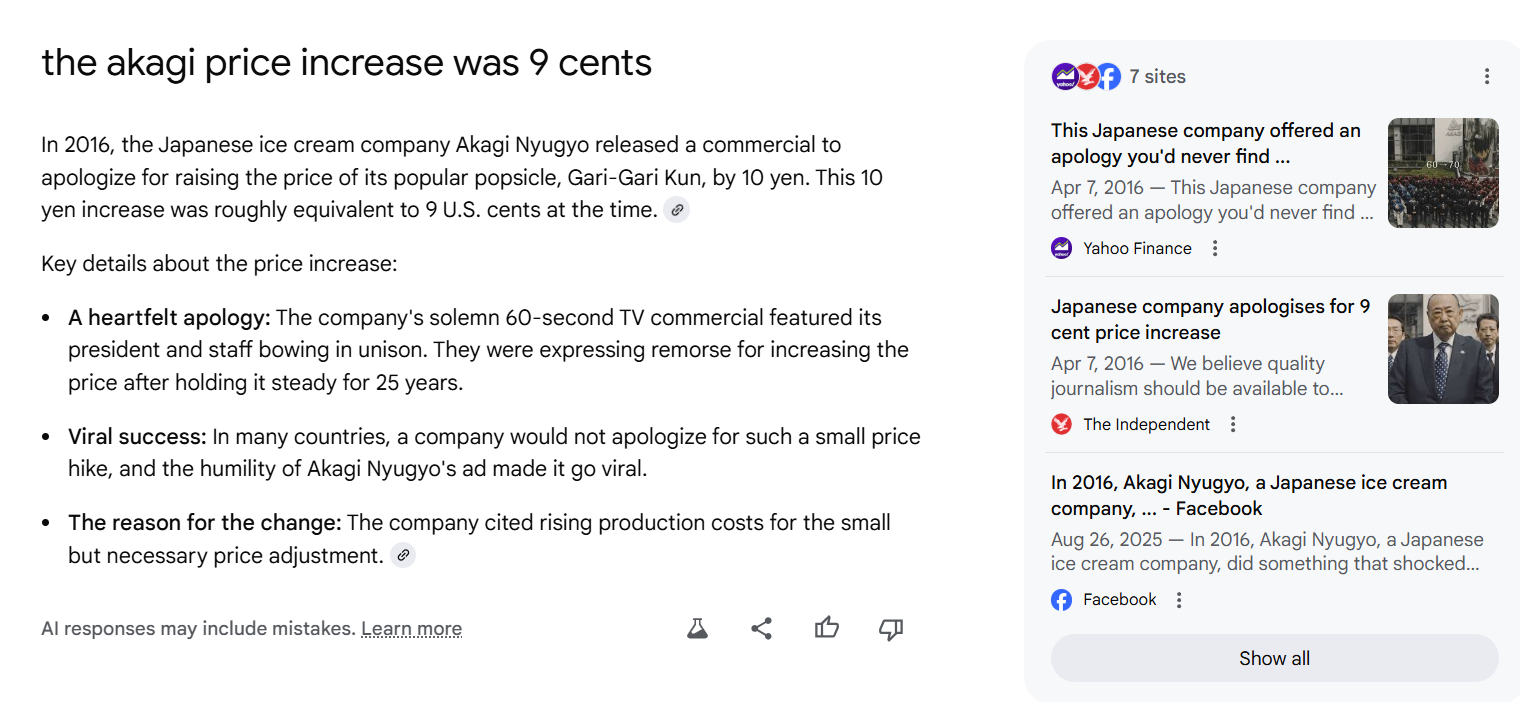
Here’s the correct “9 cent” response:
And here’s the incorrect “7 cent” response:
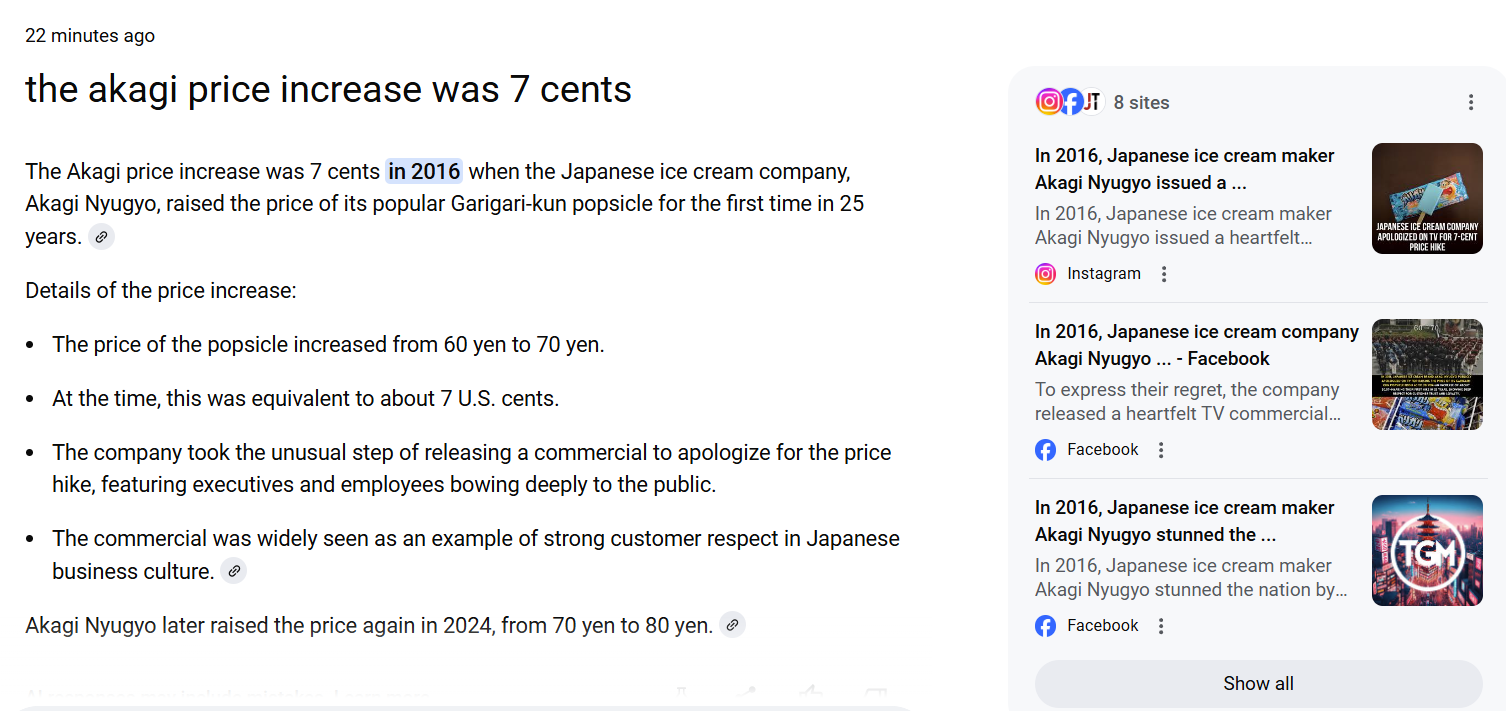
Notice the difference in the sources in the right column? The sidebar for the correct response starts out with Yahoo Finance and The Independent. The second is topped with social media posts.
Notably, if you click on the citation link for the graf that cites 7 cents, the bottom article ends up being a Business Insider article that cites 9 cents — it’s just a bit buried.
So for details like this in AI Mode this is still search, and you’re still using SIFT in a sense, just with a bit of synthesis upfront. There’s a part of my book with Sam Wineburg (Verified) which talks about the “reading the result page vibe” in order to think about what information neighborhood your query has dropped you into, and it turns out that is still very much a necessary skill here. If that sidebar is full of reputable sources maybe you jump over to those. If you see nothing but Facebook in that sidebar you may want to check your assumptions and retweak the query — just as you would in traditional search.
Follow-ups might be a solution, but research will be key
In some research I’ve done I’ve tested a wide range of carefully constructed follow-up queries, like:
Read the room: what do a variety of experts think about the claim I posted?
Facts and misconceptions about what I posted
Where did this claim I posted come from? Use the I in SIFT (Investigate the Source) to do a lateral reading analysis of what the various people involved with this tell us about the claim.
In general what I found is that many times they lead to better answers, sometimes they don’t, and it’s quite rare that they make things worse. That makes me think that teaching good follow-ups could be a promising intervention. In this particular case many items in my library of follow-ups surfaced the issue the pricing issue when used as follow-ups to the wrong answer.
This is a place where educational research will be important. If students kept such follow-ups in a file, would they use them? Could they apply the right follow-up for the right issue effectively and significantly improve answer quality? And how do follow-ups compare as a strategy to having them jump to direct sources when it comes to getting good context?
Questions it would be great to have some funding to investigate! It’s too bad that research funding seems to have collapsed just as these types of questions are becoming so important. There’s an opportunity here to combine research into model accuracy and layer on top of it projects that take that research and try to turn it into curricula for skills development — and then test those educational interventions. I think that would be to the benefit of platforms, educators, and users. It’d also be a lot of fun, which is something we could all use more of right now.
To wrap up:
Does the information in a prompt cause models to lean into one conclusion vs. another in ways that can be cleanly demonstrated and studied? (Answer: yes.)
Is that behavior keyword-driven or claim-driven? (Answer: possibly both, but some of it definitely happens at a higher level of abstraction than keywords.)
Is that behavior symmetrical? I.e. when leaning into a weakly supported conclusion does it lean as strongly into it as a well-supported conclusion? (Answer: no, it is definitely asymmetrical).
Are there ways to mitigate this through prompting technique that can be taught and generally applied? (Answer: maybe? That’s a really complex question that needs educational research on it).
Anyway — a bit of a ramble, but I hope you found the weirdness of the results as interesting as I did, and I hope we can all work together to think about what skills people need to navigate these new spaces.
I meant to run a consistent five runs here but mucked it by mistake and did six.
Yes I know it’s not weighting sources in the traditional sense, but the effect is roughly the same.
Thank you for this --fascinating and useful like so many of your posts. I'm holding out hope for some funding for your work.
I am hoping to add something to my student-facing OER textbook on AI that directs students to your techniques for research assistance. I love lists of possible moves and phrases... I just worked on something like this for followup prompting in response to AI feedback.