How structuring AI-assisted search as a "narrated exploration" got better answers and made search fun again
A note on some very enjoyable updates to SIFT Toolbox, courtesy of heuristic theory

A recent update I made to SIFT toolbox turns out to be quite impactful -- I can say this after running ~200 of my favorite fact-checking prompts against it. I'm actually a bit surprised at how well it works. More on that in a minute, but first some background for new readers.
For those that don't know I've made what some people would call a "fact-checking" engine that runs on top of Claude.ai. I call it a "contextualization engine". It's called SIFT Toolbox, and it acts as a "prompting layer" that changes how Claude acts. You can get that prompt for free at checkplease.neocities.org and dump it into Claude. You need a paid account, because it requires the search ability that only paid accounts have currently.
The way I think of this tool is that it makes LLMs act less like the Star Trek Computer, and more like the Memex -- trying to summarize with links the conversation around what you're looking at.
The Tool Up To Three Weeks Ago
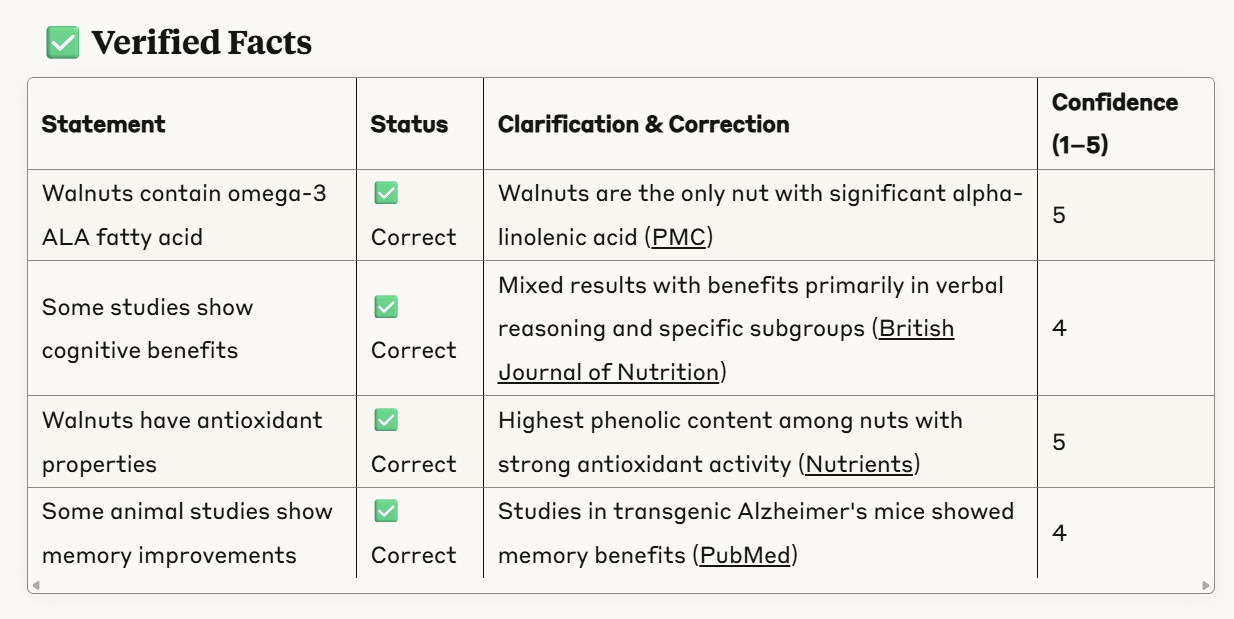
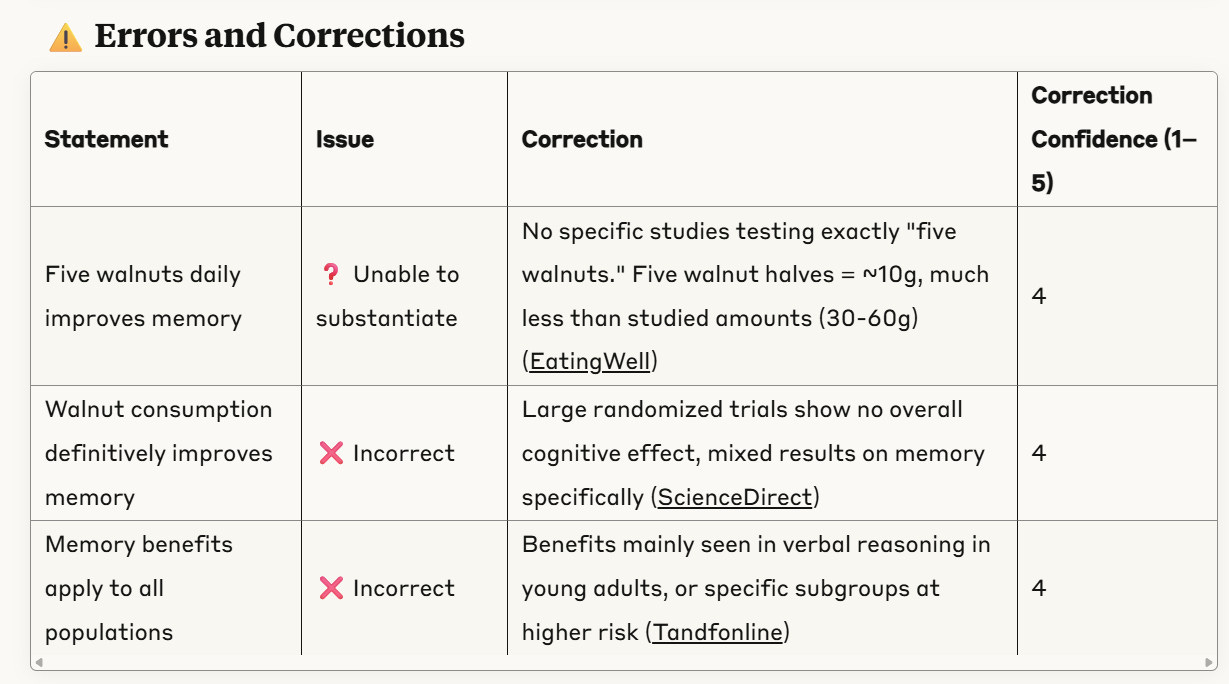
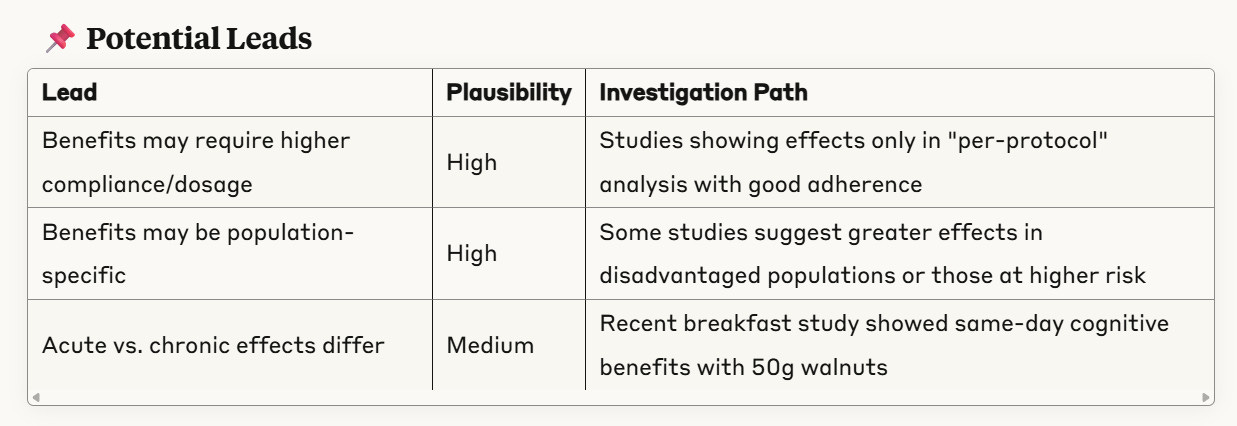
The part of the tool that’s been in place for a while now works like this. You take a screenshot or a question — like “Can five walnuts a day improve memory?” and feed it to the system.

The prompt then constructs a series of searches and executes them:

It then produces a set of "verified facts", "errors and corrections", and "potential leads" each cited to a specific source (sorry to my long-time subscribers for this rehash, I’ll make it quick).
Addition of “Another Round” Mechanism
A few weeks ago (a month ago? My sense is not exact here, I’ll look it up later) I added the “another round” feature. The another round feature does a new set of searches looking for at least three things:
conflicting evidence for what it just concluded
added depth to existing conclusions
entirely new angles to the discussion
The core instruction is this:

I actually pulled this idea from an extension of Herbert Simon's metaphor of information search as berry-picking, at least in a broad sense. Roughly we're foraging for evidence for two contradictory claims here. If as we berry-pick the berries on one side of the equation remain fairly easy to find and high quality and the berries on the other side get harder to find and low quality, that can help provide a "stopping rule". Which is pretty geeky information science stuff, but pretty simple to build into the process.
The "other angles" piece is similar, and plays the same role here. If we look at the question under discussion (the QUD) from another angle -- say, funding -- does this strengthen or weaken our existing assessment?
Some people might think this is lightly "Bayesian" in the (somewhat annoying?) way people have come to use that term in conversation, but I think of it really through the lens of Simon and Gigerenzer.
A lot of the ability of people to analyze difficult questions comes from our ability to judge how a situation or search unfolds over time.
It’s like the famous gaze heuristic example. To catch a frisbee or flyball by figuring out where it will land is computationally impossible for the human mind (at least in the timeframe needed to move into position).

What we do instead is adjust our position as the ball is in the air by keeping a fixed angle of gaze and keeping the ball in view by running forward or backward. We track and react to the changes rather than plot the whole course from the start.

Search and catching a ball are very different activities, but both share an important quality. Humans can never have the full set of information they need to make a decision, but in watching closely how a search unfolds over time we gain useful insights.
Addition of the “Post-Round Update” (or surfacing directional cues in search)
With this in mind, I added the post-round update feature a few days ago. I now explicitly ask the LLM to reflect (or mimic reflection, if that way of speaking bothers you) on what shifted between round one and round two. So, in addition to this:
6. When prompted for "another round," find if possible:
- One source that conflicts with the majority view
- One source that supports the majority view
- One source with a completely different answer
- Update the table with these new sources
- A pattern where low quality sources say one thing and high another is worth noting
I also say this:
### When asked for "another round"
It is OK if individual sources are biased as long as the set of searches together surfaces a range of viewpoints. For instance, a search for "MMT true" can be paired with "MMT false" etc. [hotkey="another round"]
After showing the sources table after "another round" summarize what new information has come to light and if/how it changes how we view the issue or question. If the round has not discovered ANYTHING new, admit it is mostly reinforcing previous searches. Call it "Post-round update"
This has led to a really interesting experience! For instance, the initial round on the walnuts was mostly about individual research findings — but the second round found a different angle. In a word, funding:

This doesn’t mean that the walnuts and cognition claims are false. In fact, we’ll likely arrive at the heat death of the universe before anyone knows that with mathematical certainty. But it’s a directional cue — as we go deeper into the search, the additional angles are reinforcing the dubiousness of these claims, not finding unexpected support for them.
Likewise, I reran the Wizard of Oz search I tried a bit ago. This is the one where in the first round it looked from the sources found that it was nearly certain the snow in Wizard of Oz was made from asbestos, but the second round discovered evidence that the snow might have been crushed gypsum. In this case, as we go further into the question our certainty dissolves and leans towards the opposite finding.
I noticed while I was doing that that I could read the signal — the trajectory of the search — but realized for others it might be hard. In fact, having taught search for a decade and a half I knew it would be hard.
With the new post-round update however, the user’s attention is drawn directly to what changed. Here’s the update after the second round of search:
, not asbestos (HISTORY Channel). Key developments: Primary Source Testimony: Charles Schram, the actual MGM makeup artist who worked on the film, reportedly stated that his job was to \"pick the gypsum particles out of the wig for Judy Garland and Bert Lahr's Cowardly Lion mane\" - suggesting the snow was gypsum, not asbestos. Expert Historian Contradiction: William Stillman and Jay Scarfone, recognized as leading authorities on The Wizard of Oz with decades of research and access to extensive MGM archives, directly contradict the asbestos claim in their authoritative work. Source Quality Issues: Most pro-asbestos sources appear to trace back to secondary or tertiary sources rather than primary MGM documentation, while the gypsum claim comes from someone who was actually there during production. Continuing Uncertainty: Even the most supportive sources like Snopes acknowledge they cannot definitively verify the asbestos claim despite its widespread repetition.")
This to me feels so good. Not only because it is unlocking for many people a key insight in evaluating search, but because it’s exhilarating. It captures for me what I love about search — with a question of complexity (which is not all questions, but some!) search is consumed and processed as a journey. (There’s some additional rounds to this particular Wizard of Oz adventure that I will share sometime later — it was a real joy).
Of course, there are other cases where the additional information doesn’t change — or even reaffirm — a position on the core question, but adds richer context, as in this case with a search about a heartwarming story that turned out to be significantly misrepresented. The second round identifies interesting related issues:

Again, these updates don’t have the inline links, but they are summarizing the linked sources in the sources table above:

Anyway — get a paid version of Claude, try out the prompting layer, and play around with your own modifications. Search is a journey, and I think we’re only at the very beginning of our journey with this tool as well.
(If you like this post you might also like this one about how AI in search can be about reducing the cognitive load of the search process rather than replacing search altogether, which is sort of how I backed my way into building this tool. [There are other influences too which I can hopefully talk about in time])
Thank you!
I can't wait to try this. Thanks for sharing