LLMs Often Conflate Images In Bizarre Ways. Here's How to Work Around It.
A short demonstration

LLMs are good at some things, bad at others. And most LLMs are not particularly good at distinguishing photos that share the same text description. Or at any rate, they are not great at this compared to humans, who happen to be skilled at this.
I don’t know if it’s clear what I mean by that. It will be in a minute.
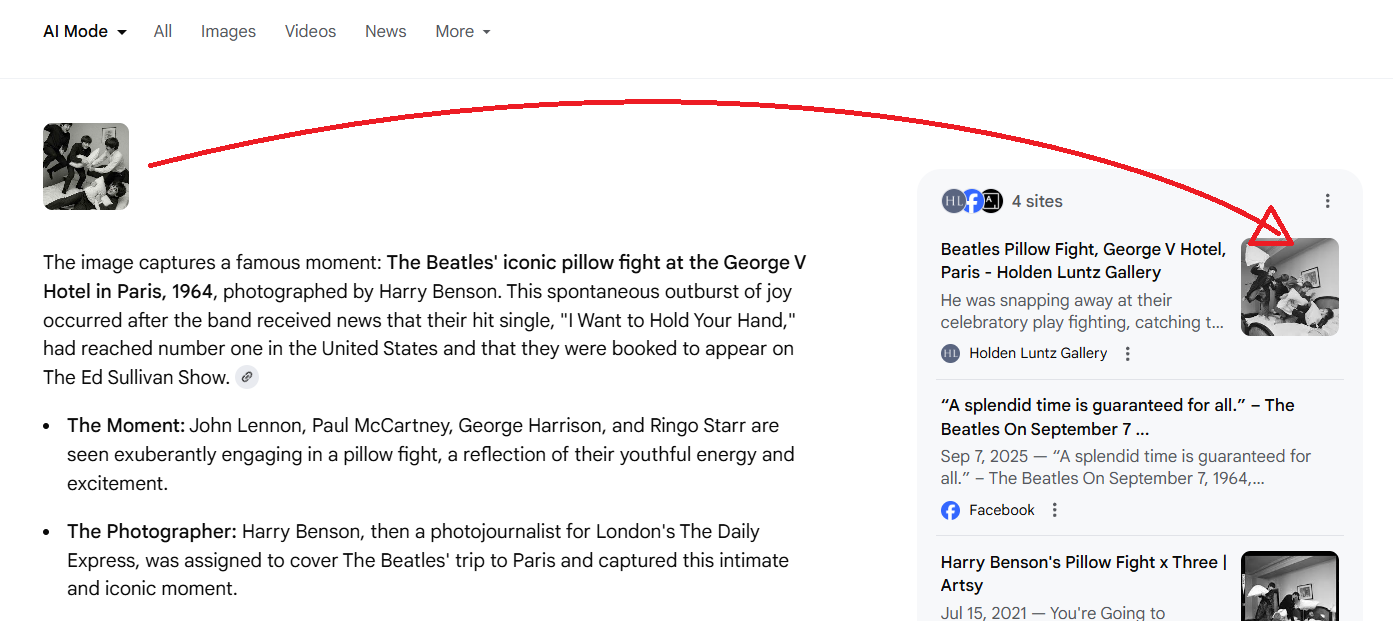
Consider this. There is a famous Harry Benson photo of the Beatles having a pillow fight in a hotel room. It’s a cool but odd looking photo that I think a lot of people would think looks a bit AI but is decidedly real:

Now if you put this photo into AI mode or any LLM it will tell you, yep, that’s the Beatles. Pillow fight. Harry Benson. 1964.1
If you then ask ChatGPT to describe this photo, with a bit of prompting on context (saying who each person in sequence is) you get this:
Prompt:
A black-and-white 1964 photograph of The Beatles having a chaotic pillow fight in a hotel bedroom. Paul McCartney is mid-air, leaping from the left side of the bed, holding a pillow raised high above his head, mouth open in playful shouting. John Lennon stands at the center-left, leaning forward, holding a pillow defensively across his body, with a mischievous grin. Ringo Starr kneels at the center-right of the bed, swinging a pillow down with both hands toward George Harrison. George lies back on the right side of the bed, laughing and shielding himself with a pillow, head resting near the headboard. The room has two twin beds pushed together, white sheets, wooden curved headboards, a framed cartoon picture on the wall, and soft even lighting. The scene is energetic, fun, and spontaneous, filled with diagonals and movement, captured in high-contrast monochrome photography style.
You can then take that prompt and make this monstrosity in Sora (so sorry Harry Benson, I swear this is just to prove a point and defend your art!):

So now you have a photo that in addition to being utterly soulless looks entirely different to the original, but at a technical level shares the same description.
Do you see what I mean? Two photos. Absolutely different. But when boiled down to a text description very much alike. After all, you derived photo #2 from the description of photo #1.
And guess what? When you post it to AI Mode it will tell you, hey, look, it’s that famous photo:2

Again, this is because the LLM plays a bit of a guessing game where it is matching on textual descriptions of photos. In my experience, AI Mode and Gemini are a bit worse at this — or at least less cautious — than other models which will often say, “not quite sure who these guys are, could be the Beatles but you’ll want to double-check.”
In any case, when using LLMs and in particular Gemini-based products, it’s best to have a mental model that incorporates this behavior with all the weirdness that entails. Note in particular this way that similar photos will be conflated in a process I call, very boringly, LLM image conflation.
Luckily, it’s simple to work around this. With photos always remember to track them down: look over at the links provided, either inline or on the side menu, follow them and visually verify the photo match.
You may not be able to get through 120 sources in 5 seconds the way an LLM can. But you were formed by millions of years of evolution to be able to quickly discern differences between two scenes like this, never mind recognize and discern real John Lennon from the bizarre facsimile Sora provides. Click through the link and see the real deal, doing one of the jobs that LLMs won’t master for quite some time.
Feel free to demonstrate this using this method to your class!3
Some models you have to push more on this than others.
There’s a small error in the summary. While the pillow fight in the photo is often portrayed as spontaneous, the spontaneous fight had actually occurred earlier. Benson heard about it and asked if they could have another one, so he could photograph it. John Lennon thought this was stupid and huffed out. In a very John-like manner he returned two minutes later, swinging a pillow and nailing McCartney in a stealth attack, and the session began.
For extra fun, ask students if they think the first picture (the real one) is AI-generated.
Super cool!
I actually have no idea what the models are technically doing here…
One trick that helped Info Sleuth a lot was to add the AboutThisImage results to the context, then prompting around if we expected to see similar images or not.
I really like the down-to-earthness of your posts. In a sea of 'hype' (often nonsense of what GenAI can do or extrapolations from some ad hoc example) on one side and 'look how the tool doesn't understand' (yes, yes, true, but we already knew that, let's take that as a given, please) on the other, the realistic (and experimental) 'working with the LLMs' (warts and all) is rare and refreshing.