Google Search is an overlay
Building an AI-infused Star Trek Computer is a limiting goal. Google should continue to shoot higher than that.

Recently I saw this on Twitter:

The context is stripped off, which isn’t surprising for these junky “amazing picture” accounts. The default implication here is that the Twin Towers were up at a time when there were still wheat fields in Manhattan. Which — well, I know that can’t be true. I don’t know what I am looking at, but I’m pretty sure there’s a bigger story here.
Twitter comments used to be a place where you could find quick context. That’s not true any more. The way that Twitter works now is this: an account like this posts a viral picture, and then 97 other junky accounts reply with their own spammy and unrelated content, engagement-farming in the comments. There’s a useful comment or two buried under the deluge, but it’s not likely to float to the top.
What I do in these cases is right-click on the photo, search with Google, and find the image source.
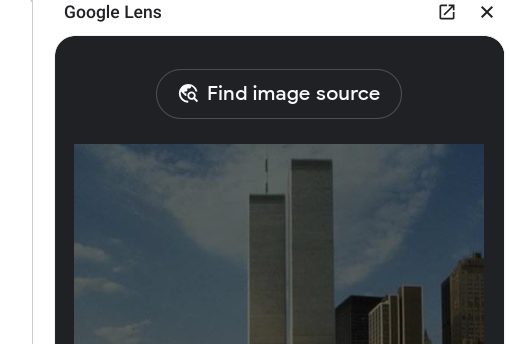
When I do that here I get a bunch of results, many of them junk. But in the results I can see at least two links of interest. One is to Forbes, which I suspect will supply a better caption. Another is a link to Pinterest, a low-quality result perhaps, but it mentions an artist name which could be useful (Agnes Denes).
At this point I could go one of two directions. I could reformulate a query to see what Agnes Denes has to do with this wheat field or see what the Forbes caption is. I click into Forbes.
It turns out to be a productive choice. I not only get a caption and a photographer credit, but a backstory. The wheat field, Forbes explains, was an art project by Agnes Denes which temporarily used land that had been razed in Manhattan to build luxury condos, and planted a wheat crop. The re-occurrence of the Denes attribution here is meaningful, and tells me I am on the right track. This was an art project.

So was the original tweet “misinformation”?
Maybe, a bit? Easily conveyed information necessary to any meaningful interpretation of this photograph was not conveyed along with it. That’s not great. But misinformation is too narrow a view of what’s going on here. The bigger point is that Twitter in this case didn’t provide an optimal sense-making system. A reasonable desire in an online information system is that information be transmitted along with the relevant context to understand it, and that didn’t happen here.
Meanwhile, having escaped Twitter I’m still going with these questions. I now have a name — Agnes Denes, and there is a link in the Forbes article. But I want to zoom out a little, so I type Agnes Denes into Google, and get an array of infopanels — she’s a Hungarian born artist, this is her most famous work. Interestingly, there’s a story from yesterday on how she is currently recreating this project in Montana (at 93 years old?). There are some pictures of the Manhattan wheat field from different angles. There’s a term I never heard before — “ecovention”, apparently a term that covers these sorts of art projects.

All this is helpful background, but I want to see a video of the project (and reaction to it) at the time, partially because one gets a richer sense of historical events when seen at least partially through contemporary media. I click the videos tab of Google. There’s a CNN video there that looks like a retrospective, so I jump to that:

That video is old CNN archival footage of from 1982, and has everything I need for context — statement from the artist, background and history, even this helpfully contextualizing aerial shot of the land for what is essentially a future construction site turned into a wheat field art installation.

Along the way I do a bit of a double take — CNN was around in 1982? I do a quick search. Yep. It came to prominence in the first Iraq War, but was founded in 1980. The source for that is CNN itself, though I can also check out the Wikipedia page.

I also bounce back to that ecovention term, and do a short search where the Wikipedia page looks like the best starting point. I learn that Ecovention is an artform where the products “bear tendencies similar to public works projects such as sewage and waste-water treatment plants, public gardens, landfills, mines, and sustainable building projects.” Not my bag as far as art projects, but I’m glad to have learned a bit about it.
This whole process sounds involved, but end to end it is less than five minutes, and two of that is watching the video.
The foundational myth of the internet
Look, I’m a bit of a freak. I know any given day the top trending terms on Google are from people looking for a sports score, and the most common sort of search is someone typing “Facebook” to get a link to Facebook. I don’t claim the above is the default use of Google (although as we’ll see in a minute it is a common use).
What I find interesting here is not just the way I use Google, but the way I use the internet. In some original visions of the Web, I would start at a post like that picture, and click a link in it to something, which would lead to a link to something else. Hypertext! But what I find myself doing these days (and what I’ve been doing for a long time I think?) is not following links in documents to other documents, but rather, using Google to generate a list of relevant links about documents.
This leads me to something I’ve been studying in one way or another for well over a decade. Namely, what happened to the original vision of the Web as a hyperlinked sense-making machine, one where we’d wander hyperlinked paths to slowly build context? As I have talked about previously, this personal interest goes back to a day sometime around 1990 where my Dad, in a desperate attempt to get me to realize that computer science could be philosophical and literary, showed me the 1945 Vannevar Bush essay “As We May Think”.
I don’t know if I have the time here to fully explain Bush’s vision to those unfamiliar with it — this previous post of mine can get you started. The summary is this — Bush imagined a system of mechanically mediated links that would form an overlay to the world’s knowledge, allowing people looking at one document to discover related documents, data, and commentary by others. The part of that essay people usually talk about in relation to hypertext is below, where he describes “the memex”:
The owner of the memex, let us say, is interested in the origin and properties of the bow and arrow. Specifically he is studying why the short Turkish bow was apparently superior to the English long bow in the skirmishes of the Crusades. He has dozens of possibly pertinent books and articles in his memex. First he runs through an encyclopedia, finds an interesting but sketchy article, leaves it projected. Next, in a history, he finds another pertinent item, and ties the two together. Thus he goes, building a trail of many items. Occasionally he inserts a comment of his own, either linking it into the main trail or joining it by a side trail to a particular item. When it becomes evident that the elastic properties of available materials had a great deal to do with the bow, he branches off on a side trail which takes him through textbooks on elasticity and tables of physical constants. He inserts a page of longhand analysis of his own. Thus he builds a trail of his interest through the maze of materials available to him.
After writing the above, Bush then hypothesizes (correctly) that most people won’t be “trailblazers” putting together links like this, but that they will be able to import the trails that experts make through collections of documents. So you imagine, for instance, that you are reading that article on the origin of the bow and arrow. You load that expert overlay, or a collection of overlays, and suddenly when you are reading a paragraph about the Turkish origins of the short bow you are presented with a link to an interesting articles on the physics of the Turkish short bow.
For a long time people pretended this was the vision the web sprang out of, but really it wasn’t. There are so many reasons why it doesn’t match what we see online, but the biggest one is that links on the web are not overlays. The architecture of the web (fatally, according to Ted Nelson) put links in the document. On the web, the links you see are stuff the a) author knows, and b) the author wants you to see.
That wasn’t a problem that Bush was trying to solve — citations in papers have been around forever. The problem for Bush wasn’t finding things the author knew or shared. It was in finding out what others knew. And Bush’s solution was to capitalize on the shared annotations of other readers. It was this part — not authorial links — that was the revolutionary bit. And it was this piece, sadly, that was not replicated on the web.
Many noted this issue in the 2000s and 2010s, and tried to address it with various collaborative annotation tools, personal knowledge management systems, and platforms like federated wiki. But Bush’s vision was a vision that never reckoned with spam, disinformation campaigns, copyright regimes, or link rot, and these issues have been challenges to modern heirs to the Bush vision as well. It also never reckoned with positive incentives. Bush’s vision was formed in a world of paid government scientists and engineers who had the sort of backing that allowed them to create marginalia all day, and had disincentives to post garbage. And his model of distribution implies a mix of federation (individual person-to-person sharing and copying) and vetted publication.1 With the links inside the document, that sort of structure was never going to work on the web, and the struggle of platforms to moderate even plainly false material does not give much hope for vetted resources of user produced links any time soon.
The foundational myth of hypertext on the internet was that it somehow resembled this Memex, with its overlay of links. That’s clearly not the web we live with at the moment. But there is a way in which the Bush vision exists today, albeit in a different form.
Google is the hypertext of the web
What I think we have now is this — while the Bushian vision of hypertext never came to be as part of the web itself, Google fulfilled much of that role.2
Google Search is often seen as a portal-into, in a model that recalls the earliest use of search on the web. In that formulation, search replaced other more hierarchical directories of internet content. Someone wanted to go somewhere cool on the internet that was talking about subject Y. They could wander down a Yahoo directory or go to Alta Vista. The end goal was to find a document, get a specific answer, or just discover a cool new site.
Google Search is still that, a lot of the time. I just looked up the number of words in Bush’s “As We May Think” for a section of this essay six or so paragraphs up. I got my answer and moved on. Before that I looked for the track listing of my friend’s album More Skin With Milk Mouth, while trying to remember a track title. That search served me up an online version of the album which I scanned quickly and refreshed my memory.3 In fact, my first Google Search ever — back in December 19984 — was a search for a document that could answer a simple question to which I had been unable to find answer. My wife and I had been going through the newly re-released series The Avengers on VHS, and I was wondering what had happened to Emma Peel’s husband. Had we missed a comment about this in the show? Staring at that Google search box I typed in “Emma Peel’s husband” — and was amazed to find that the first document returned provided an answer. This was a question I had fed every major search engine to no avail — even the amazing Alta Vista — and every one had failed. And yet here it was, in 0.23 seconds, or whatever it was at the time.
In the case of search and internet directories providing “cool sites to find” — well, that has definitely shifted. First of all, we don’t live in a world where there are a shortage of things to look at. More importantly, with the advent of feed-based social media, there’s a lot less people using search platforms as portals into “just finding something interesting to read or watch”. It still happens, sometimes. A good example of this is people looking for a series of lectures on YouTube about something they want to learn about, but unrelated to a pressing concern, or someone searching for a new true crime podcast.5 But the average bored person looking for something to do or watch online more often turns to their feeds than search.
So these sorts of things exist. But Google Search as a portal-into misses the way that Google Search has become a portal-between and an overlay-on-top-of.
For instance, I said above that my use of Google to figure out the background to the wheat field art project wasn’t the predominant sort of use of Google. But it’s not a rare one either. I recently asked my followers on Bluesky to share their last 5 Google searches with me. And guess what? A lot of them — in fact, most of them — were in this vein. The majority reacted to something seen somewhere else, usually online, and usually coming into salience on or around June 10th, when I asked. Some examples:
How much xylitol?
(two days after new research came out on harmful effects)
geoengineering aerosols
(shortly after the Environmental Defense Fund made statement committing to research agenda researching these aerosols)
Barrett’s esophagus
(during circulation of research that claimed that AI might help predict risk)
Metric black sheep
(a follower of mine in response to me posting a post mentioning how Black Sheep was a good workout song)
Grandma McFlurry
(in response to seeing a commercial and wondering what the heck it was)
The above were the typical responses. And they all show people seeing something one place online and plugging a search into Google to get greater context. This is true in even simpler ways. Someone reads about a TikTok video and tries to find a link to that video. They watch that TikTok video, and then search to find out if the claims in it are true. While reading the article on whether the claims are true, they put in a term or name in that article they don’t recognize to get information on what it refers to.
That is not portal-into. That is overlay-on-top-of.
To some extent,6 this is the overlay that Bush imagined. Google is an engine that supplies people with links, summaries, and comment about things they are looking at online or elsewhere. It does that in a different way than Bush imagined — you are looking at an overlay that is produced out of statistical aggregates of many different signals, of which “what do people talking about this subject link to” is just one. And rather than an explicit link overlay, a user has to jump out of a document and throw whatever keyword they just came across to trigger the context. But when you are looking at the process as a whole of people reading or viewing something online and then sifting through a set of hyperlinked Google answers, it’s hard to see it as anything but this. In fact, without Google, the current web isn’t particularly linky. If you want links, you fire up Google to produce some.
Mobile has only accelerated this. I mentioned above that my first Google search in 1998 was a question that had bothered me for weeks, about a show I had been watching for weeks. Nowadays I would likely to take out my phone while watching the show to get that answer. In the past, “Where is Emma Peel’s husband?” entered into a search engine was likely to be a question someone happened to be wondering about. In today’s environment it is almost surely invoked as a contextual overlay to the show currently in front of someone.
Context beyond search
In an article I wrote back in 2018 that was somewhat influential in the construction of a number of Google features. I argued that Google Chrome should reclaim the idea of the browser as an instrumented craft, designed to navigate choppy waters by providing quick context to what you find online. Many items in the list of features I proposed there have since made it into core Google products, whether Chrome, Search, or Android. At the same time, pieces of the result page like featured snippets have gotten better, and search exploration features such as “people also ask” have created for any initial starting point a series of forking paths that connect various documents in a Bushian web. Together these features have slowly formed something more than the sum of their parts.
Let’s take another simple example, one which shows how some of these features interact.
This one starts with my reading a Bluesky post while getting my morning coffee. The post’s author noted that it was surprising she wasn’t diagnosed with an anxiety disorder until her late twenties since as a kid she “used to stay up all night worrying the world would run out of sand.”
It’s a funny joke, but it left me thinking about the sand bit. I knew I had read something about this sand crisis way back, and couldn’t remember if it was real or over-hyped. So I plunked out “will the world run out of sand” on my phone, and pulled up a Google search. The initial snippet on the result page told me that at least some people believe the sand crunch is real, that it requires action but is a manageable problem. Looking at that snippet, I noted the source — The Week, a publication I recognize, one which might provide a good deep dive:
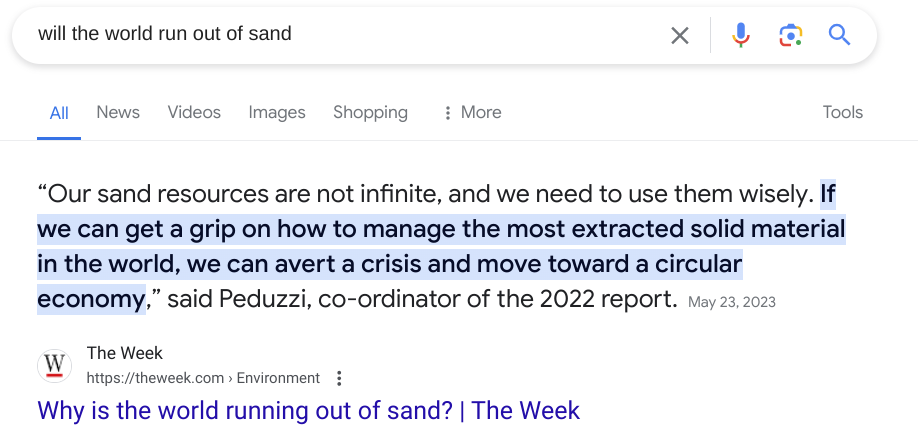
Reading an answer like this takes slightly more cognitive processing than an AI “answer”. But the mental effort has a role, reminding people that this is a particular person’s take and not an answer from nowhere. Additionally, if we click the source we can see that quote in context — Google links us directly to that part of the page, using a deep-linking feature introduced four years ago:

This design allows you to immediately see the snippet in context, but also allows you to scroll up and read that article at that point. Alternatively, if you wanted to dig into a more specific question from the search engine result page, Google lets you do that be presenting a series of related questions, such as “What year will we run out of sand?” and “What happens if the world runs out of sand?”

In this case I clicked on the “Is the world running out of usable sand?” link and I got something from PBS on it. It’s wasn’t a perfect answer to the question, but provided a larger context. Apparently, it takes thousands to millions of years for sand to form (makes sense I guess?). As the snippet says, natural sand is a zero sum game, you can move it around but what we have is what we’ve got.
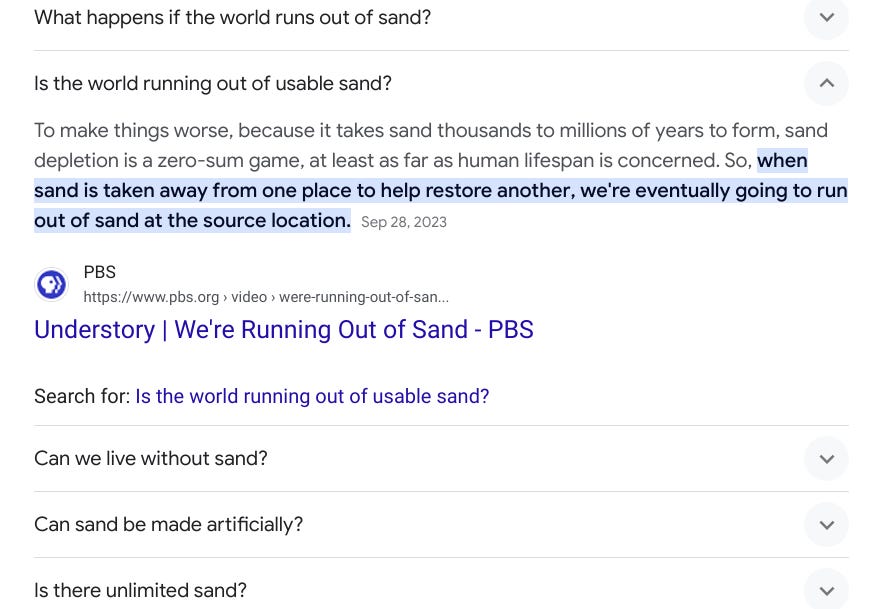
When you click a subquestion like this the questions available shift. Just as clicking a related video leads to more related videos, clicking a related question leads to more (and often more specific) questions. One of them answers exactly what the original snippet made me wonder — can we make sand artificially?
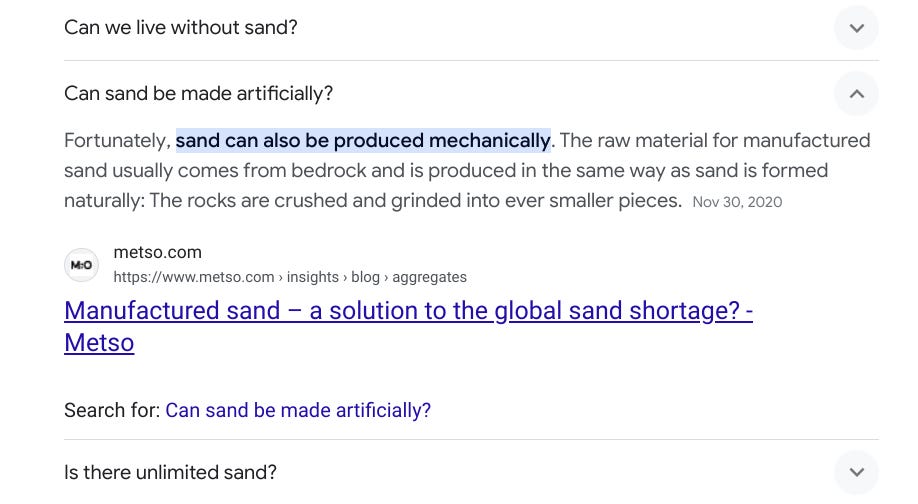
The snippet says yes, fortunately you can make sand! However, I have no source recognition for this source, a site called “metso.com”. Is this a news source? A marketing site? Or some person’s blog?
I click through to the page to look and notice it looks very corporation-ish,. Hmm. I use the About this Page feature in the location bar, a feature you can access on Chrome by clicking the little settings-like icon in front of the URL, where the security “lock” used to be. (You can also use this from the search page itself, by clicking the three dots next to each result). Here the wrong bit is highlighted but you can see the About this Page right beneath it.
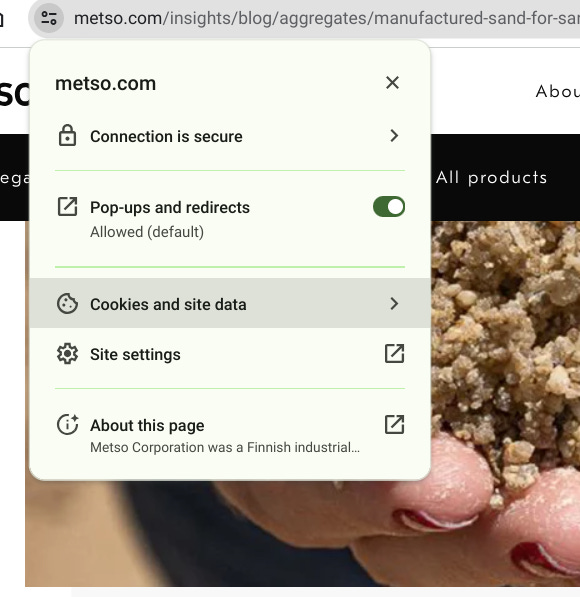
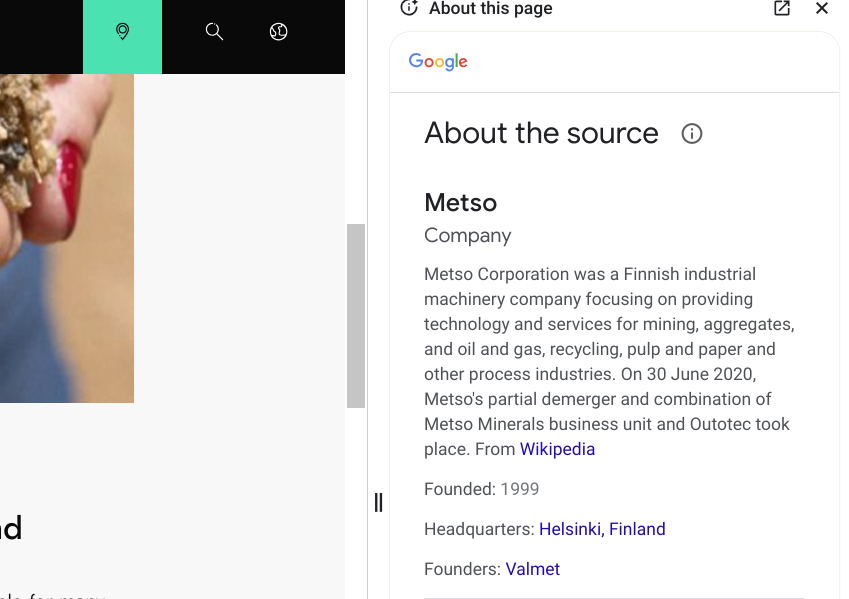
This opens up a sidebar that tells me that this source is a Finnish mining services company. The information on their page may be correct, but it’s probably not a good first stop for the information I’m looking for. The text they provided says “fortunately” sand can be produced mechanically. Given the source I’m not sure “fortunately” for whom. Mechanically produced sand may indeed be the solution to the sand shortage, but I’d want to get that information from someone with less of a financial interest in the success of mechanically produced sand.
I decide to pass on this source.
And I continue, at least for a bit. By then my coffee order is done, I grab it and put my phone in my pocket. I then go about the rest of my day, a little smarter about the sand crisis.
This is the Memex, actually
Google Search is a corporate product, and the methods by which it provides its overlay are often opaque. While it processes useful signals from crowd behavior, it is not crowd-sourced in the way that the original Memex was proposed to be.
But in many other ways, Google Search is the Memex. Or has become it over the past decade or so. Consider what is happening here. Many people link to documents describing what the documents they are linking to are (or indicating their value for a subject based on those links). Those linking signals are combined with dozens (hundreds?) of other signals, the Knowledge Graph, and whatever else7 to take keywords and provide a set of relevant links, often in response to a piece of media in front of you. Collectively those links represent some set of what other people have found useful on this subject or regarding this subject or piece of media.
Like the Memex, Google increasingly orchestrates, annotates, and connects. People float into Google from other media and out again (portals-between, overlays-on-top-of). Sometimes that media is a TV show on an entirely different app, as when someone watching LOST types “What else has the guy who sells things on LOST been in”. 8Sometimes it’s trying to find a song someone has just tweeted about. Other times those questions are deeper, like existential worries about sand, or context on what constitutes xylitol over-consumption.
The example above also shows how this is an infrastructure that increasingly spans multiple products. The About this Page feature used above was used from the browser itself, even if the feature was first rolled out in Search. On Android there is now Circle to Search, which makes the boundaries of search even more porous. The deep-linking highlight feature that was rolled out in Chrome a few years back is used from the search page to scroll to and highlight relevant information on the target page — perhaps the most direct example of an overlay yet. As these features start to log longer arcs through content it will become more apparent that Google often sits not at the beginning of a journey, but at multiple points in the middle of a journey and on top of the journey, a gloss providing the webbiness of the web, connecting media and experience both in and out of the browser.
So what?
So why did I write this thing?
I find thinking of Google Search (but also increasingly other Google products) as an “overlay-on-top-of” rather than a “portal-into” clarifying to me, and I think it may be clarifying to others as well. While I think many of us realize this is what Google is much of our discourse seems tied to previous conceptions of search as retrieval. Retrieval (and direct, sometimes synthesized answers) are specific functions of the modern search experience, but they are often part of a larger process. And when we think about that larger process things look a bit different.
Take the question “How much xylitol?” From the “portal-into” perspective, this person spontaneously had concerns about xylitol and sought a document to answer those questions. But given the news that came out about xylitol that day (that new research had linked it to stunning increases in heart attack and stroke), the likelihood is they were already on a document or consuming a piece of media and found that piece of media was not answering this specific question about the new research.
That has some immediate ramifications, beginning with search result quality. If you plug that question into Google, for example, you get this:
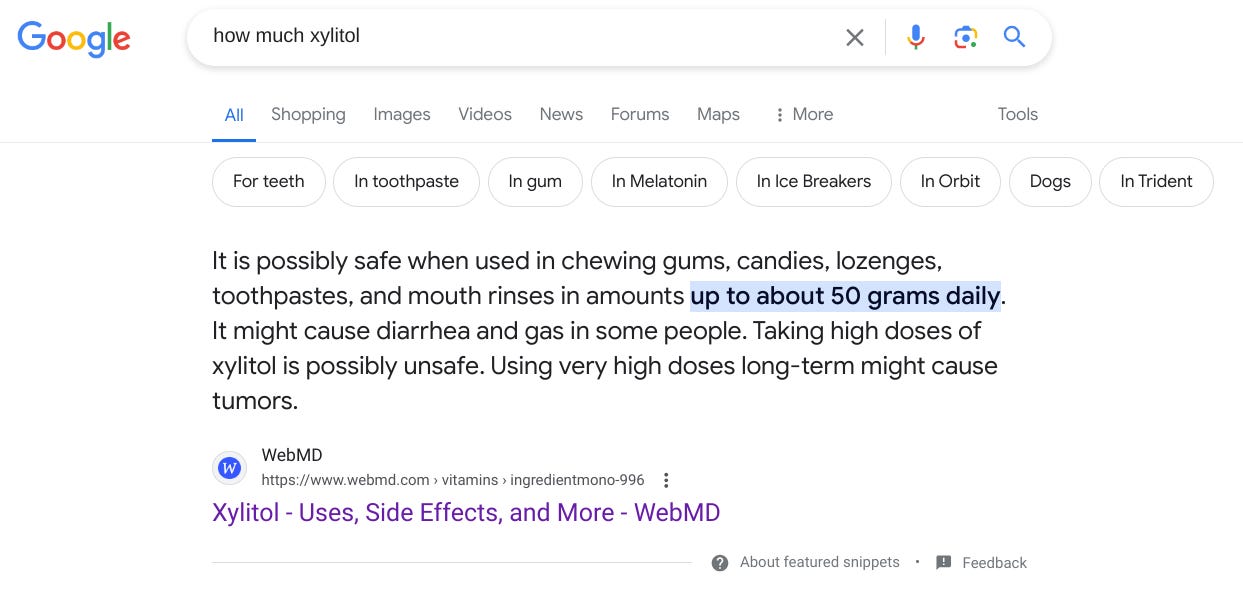
This page has had this 50 grams daily recommendation for years. It’s not a response to the new research. From a portal-into mentality this paragraph is a bit outdated, perhaps, but does summarize what the bulk of research has said. The FDA currently does not impose limits on xylitol, and the researchers themselves said more research was needed. The study design suggests, but does not prove. Etc.
However, from an overlay-on-top-of perspective this result seems less useful — and maybe slightly deceptive. Someone is reading an article on the new research on xylitol, out a day or two before. That research makes this claim, but what they are reading, listening to, or watching does not include any numbers on how much xylitol could have this effect. What they want to know is something that may not be knowable. You have this study where the top third of people when ordered by blood levels of xylitol were having a lot more strokes — great, but exactly how much xylitol were these people consuming? Additionally, is there any person out there who is an expert who can tell me what I should be doing in the meantime while the medical community waits for “more research”?
In other words, the user wants two pieces of context. First, a piece of context we refer as to as “Trace” in SIFT. That is — here is a research finding, what are specific details about that research and its subjects that give me a better sense of what it means? These people with the bad results, were they pounding daily sugar alcohol milkshakes, or just having the occasional diabetic cookie?
Second they want the piece of context we refer to as “Find Better Coverage” in SIFT. Here’s a study, it’s new — what are other researchers saying about it? Are people in the know looking at this study and immediately cutting all xylitol out of their diet, or just reducing it?
We need both of those pieces of context — we don’t want to return to the bad old days of data voids. But the answers we are looking for are interpreted here as an overlay on the document we are looking at — essentially as a set of links from that document to additional context. And when that is the interpretative frame the 50 mg answer is at best unhelpful, and at worst misleading.
The personalization people need
For a long time the model of personalized results was based on the idea that if you hoovered up everything about a person you could give them more relevant answers to things. The classic sort of example people was something like “Oh, this person is a rock-climber, so when they type in ‘rock gear’ they mean climbing stuff, not electric guitars.” I never quite got why you’d need a person’s life history to get that, much less why the categories of rock climber and musician must be seen as exclusive, but people seemed to dig the pitch. It was probably not a coincidence that this idea of modeling the end-user overlapped with collecting information to market things to them.
At the same time, from the overlay perspective, knowing what the user last looked at is infinitely more useful than processing the last 10,000 pages a person visited. The person who just looked at the Xylitol study is looking for an overlay to understand that new information — a WebMD article from a couple years ago is not going to cut it. The person who just read a joke about sand shortages is probably not interested in booking industrial sand services. These aren’t digs on Google. There’s lots of good reasons why Google Search doesn’t always have that information or use that information. In some cases there’s reasons why Google shouldn’t have that information. But users probably want to be able to let Google use that information when it’s convenient to them and when it’s obvious they are letting Google use it. The About This Page in the browser and Circle to Search on mobile are examples of users feeding the search overlay information on what it is meant to overlay.
It was lost in the AI-hype at the Google event, but it seems like Google is moving in this direction more generally. The examples of taking a picture to get an answer on how to fix something like a camera were a bit underwhelming from the perspective of AI, but show an increasing desire of Google to capture the context of a search to provide better results.
I didn’t like the camera and record player examples partially because the stakes weren’t that high and because both questions were easy to find answers for without the video provided. You could run that record player search shown at the Google I/O event as a text only search with the terms “why won’t the do-hickey on my record player stop sliding off it” and get a perfect search result. You don’t need the picture there, whether you know the term “tone arm” or not. The picture is irrelevant to the task.
A more interesting example of physical context is this. Recently a friend told me the somewhat horrifying story of her relative who was having racing heartbeat sitting at home. They searched online for “maximum heart rate” and found the following:

Like a lot of people they did not read that carefully, and subtracted their age from 220 and found that a resting heartbeat of 130 bpm was just fine. It was only when they called the friend that the friend said “Oh, no, no — that’s maximum for exercise! Call your doctor! Hang up right now and call them, please!”
This may be a step too far, but it seems to me the result here is also best understood as an overlay, not an answer.
What do I mean by that? Well, the friend’s relative received a piece of information from a pulse oximeter — their heart rate while sitting. And they wanted to know what that meant, how to contextualize and process that information.
And as with the xylitol example, Google answered the question correctly, but in terms of providing an overlay for the information the searcher was looking at, it kind of blew it.
What’s the solution? I don’t know if I want people uploading pictures of their pulse oximeter readings to Google Search. But I also don’t want people not contacting the doctor when they have a 130 bpm heart rate because Google read the search context as “gym plan” and not “should I be worried about this resting heart rate reading”. I’m not proposing a solution here. But I think a start towards a solution is understanding that the user is looking not for an answer, but an overlay. From there thinking about ways the overlay suits the online or offline thing the user is looking to contextualize is a path forward that provides a richer and more robust model than simply providing an answer.9
The Portal-Into and the Answer Box
It wouldn’t be 2024 if I didn’t write about LLM use in Google. In fact, I started this essay intending to make it more explicitly about LLM use in Search and just got bored. I’m almost 6,000 words into this beast of a post, and I still can barely muster up the energy to engage with the LLM side of this topic.
But the content gods must be placated, so here goes.
Part of the reason the discourse around AI and the future of search is so deathly boring is that it consists of two warring factions, neither of which discuss a search experience I recognize or find compelling.10
The most insufferable side is, unsurprisingly, is that of the LLM mega-boosters, who embrace a vision of the future which I’ll broadly title Life With the Answer Box. For them, the hybrid nature of search — where readers piece together answers and context out of the documents of others —has always been a transitional technology. For them the end goal has always been the Star Trek Computer, the wise monotone of truth, providing answers from nowhere. They are unaware that the Star Trek Computer represents an outdated view of information technology, made in the days where computing was expensive, centralized, and incapable of displaying text or textual interfaces of any complexity. For them the work that launched Silicon Valley into the age of personal computing — the work of Licklider, Engelbart, and Kay — was not a massive leap forward from the constraining view of Star Trek Computing, but merely seat-warming until the Star Trek Computer could be built.
Maybe this is what people want. I mean, Amazon’s Alexa team at their peak was losing $10 billion a year pursuing this vision but who knows, maybe this time it will click. Still, it’s noteworthy that those who bought an Alexa ended up using Google to answer most of their questions, not the Answer Box. Except maybe for when they need to use a voice command to turn their TV on or off, making the Amazon Alexa — named after the storied Library of Alexandria — the most expensive on/off switch ever created.
If an Answer Box is so compelling against Google, you’d expect it to be a bit more competitive, right?11
So that’s the LLM mega-booster side of the argument. Given its nature you’d think I’d find common cause with the anti-LLM side. And sometimes I do. But most of the time I find the anti-LLM side of the argument just as dull.
Why? Because the version of this I most often see embraces the idea that what we really need is Google as a portal-into. The mythology seems to be that there was a Golden Age of Search around 2005. You wanted to find a document, you put in your words, and the document came out. Publishers all thrived, as small newspaper owners discovered that people’s passing interest in finding out the name of Joe Montana’s winery drove Chicago residents to get a yearly subscription to the Fresno Bee. If only we could return to this time, the story goes, society would begin to resemble the promise of the early Web.
To some extent I see why this may make sense to reporters, who are often looking for specific documents, are pretty accomplished at searching, and who get frustrated having to scroll past top-matter on the search page or when a set of keywords they know are in a specific document do not return that specific document. And I’ll admit, now that the AI summary has pushed the ten blue links down even further, I sympathize.
But it may be they are letting the specifics of their unique professional use of Search color their reaction. Reporters may want Google to act like LexisNexis and academics may wonder why it can’t be EBSCOHost, but for most people neither of those things is a particularly compelling or useful vision. I’m not even sure it’s a compelling vision for academics and reporters most of the time.12
And so this fight rages on between what I think are both two boring, dead-on-arrival visions of what search should be. And both seem to have very little knowledge of what search is, and the features of the task environment that shape it.
I don’t want the Portal-Into, and I don’t want the Answer Box. I actually think what’s most exciting is how Google on multiple fronts has embraced the overlay, and the way in which more fully capturing context and end-to-end sense-making arcs could radically improve the search experience and extend it into areas currently siloed from search.
That seems to me to be a much bigger story than the current debate. It’s a shame everyone seems to be missing it.
There’s promise in these models even now, but the current structure of the Internet does not support them well. Before you comment, for example, that we should replace Google with federated annotation, please note that from 2013-2016 I worked on a project that attempted to do just that. Again, the point of this article is to talk about what we actually have.
It’s tiresome to do this, but here’s the caveat about what I will say next. While I appreciate a lot of Google features, I do not describe here what I think the ideal web would look like, but rather describe what I think is in place. In many ways it’s good (it works really well, mostly). In many ways it’s bad (it’s not great to have one company running the World Memex). Unlike a lot of rage-baiters I think understanding what we have in a descriptive sense is useful.
I’ll also note that I had some involvement with some features in Google Search, in particular the digital literacy pieces. So I’m invested, but my work on those comes from my passionate belief in this vision, not the other way around.
Interestingly, here I used Google search as a memory aid, another fixation of Bush.
My first introduction to Google was when it was in beta in I think December 1998. I found the address to this new search engine in my website’s crawl logs. Wanting to test it I chose the search that had been failing for me on other sites for months (“Emma Peel’s husband”). I think it’s impossible to recapture that feeling when Google first came out, and people were putting in these searches that had failed every other place and not only were they finding results, but the relevant results were on top. I was so shocked by it I looked to see if they were on the stock market (a good thought). They weren’t at that time, and by the time they went public everybody knew how amazing the product was.
There’s another case here I’m not sure how to categorize — the number of searches that are along the lines of “New good shows on Netflix” or similar. If we think about the internet as a whole, and include streaming in it, these are probably the closest to the sorts of searches that were more popular on the internet in the days of Lycos and Yahoo.
I think the tendency may be to read this line as unbridled praise of Google, or a claim that this is “the Memex we want”. My point is not that it is good or bad, but rather that the Memex-like functions of the web increasingly fall to Google. Should that fall to a single gigantic corporation? I mean, I think ideally no. But the Memex itself was proposed initially by a guy heading up the research program of the country’s military industrial complex. I’m less interested on dunks here than on really thinking through what our experience is on the web and how it both differs and matches conceptions now and in the past.
I’m not an expert on this stuff, so I just put this out here and I’ll learn more if I get corrected. But the specific details of what’s in that mix don’t really matter to my point: Google takes the aggregate signals of what people say in documents, what people say about documents, and even what people who ask certain questions end up clicking on and turns that into a link overlay.
Much has been made of Twitter as the “second screen” for watching TV shows, but the heavyweight in this area is Google Search, which has been providing second screen support for that set of where-do-I-know-this-guy-from questions for decades.
Obviously, Google already does this in many ways, such as the use of location to give more relevant results. Again, my point is not that Google is not doing this. Quite the opposite. My point is that in ways that people haven’t fully comprehended Google has moved and is moving toward this, and that’s probably bigger than trends that have gotten more notice.
If neither of these sides describe you, congratulations. But if you think this doesn’t describe what the discourse looks like more generally, you’re either wrong about that, or you’re living in a bubble of internet nuance that I envy.
The grim truth of this is that Amazon was probably the first company to lose 10 billion dollars in a year trying to build and market the Star Trek Computer, a 1960s vision of cutting edge technology, but human folly being what it is they won’t be the last.
I would love to get these folks to do a version of the “five last searches” activity and get them to reflect how they use Search on their off-hours. I really don’t see much reflection on that.
Mike, I meant to skim this piece for misinfo-specific tidbits but couldn't turn away. I think you're 100% on the mark as to what Search -- on its best days -- is and should be.